【www.zhangdahai.com--其他范文】
陈立伟,董睿婷,王桐
1.哈尔滨工程大学 信息与通信工程学院,黑龙江 哈尔滨 150001
2.哈尔滨工程大学 先进船舶通信与信息技术工业和信息化部重点实验室,黑龙江 哈尔滨 150001
随着车辆保有量急剧增加,城市中停车难问题日益加剧。尤其对于城市中心,停车资源与停车需求的极度不匹配导致道路拥堵严重,停车资源分配不合理造成停车场服务效率不平衡。因此停车场外停车诱导方法亟需着重研究,互联网的快速发展也使得智能场外停车诱导[1]成为可能。
针对场外停车诱导问题,Rajabioun等[2]和Xiao等[3]基于模型分析停车信息的季节性和时空相关性,对未来的停车可用信息[4]进行预测,得到未来去往各停车场成功停车的概率作为诱导依据。Badii等[5]和Yang等[6]等分别采用统计以及机器学习的方法对成功找到停车位的概率进行预测。这些依赖预测概率的方法在停车需求大时并不可靠,且容易受到运营模式和特殊事件[7]的影响。王韩麒[8]考虑双目标函数的约束,基于灰熵理论,构建场外停车诱导模型,以提高区域范围内的停车率。Boyles等[9]模拟单个驾驶员的停车搜索过程,根据驾驶员过去访问停车场的记录设置先验值,完善马尔科夫模型状态空间。Liu等[10]利用瓶颈模型分析停车场收费标准和管理模式对停车时间等造成的影响。常玉林等[11]采用排队模型研究路径流量与停车场可用性的关系,提出随机用户均衡模型。陈群等[12]考虑总行程时间以及停车场的周转率,对停车位分配进行优化。然而这些方法都只考虑单一用户的利益最大化,而没有考虑到所有发起停车请求的用户之间竞争合作的博弈关系,所以会出现对某一用户车辆最优的停车诱导策略,对整个系统却远远不是最优的。
本文在多车停车需求的情况下,考虑全局利益,引入强化学习(reinforcement learning,RL)方法提出一种基于强化学习的智能场外停车诱导策略,使停车效率最大化,平衡所有停车场的停车占用率,以减少停车搜索对城市拥堵带来的影响。
停车信息包括用户停车时间及目的地、停车场所的位置及车位占用率等,停车信息的获取是进行场外停车诱导的前提,通常由车载联网系统以及传感器设备等可以实现实时获取停车信息。本文采用预订机制完成未来停车信息预测模型。
1.1 车路协同通信架构
在智能交通背景下,通过部署路侧单元(road side unit,RSU)形成车路协同(vehicle to road side unit,V2R)通信架构,将停车诱导系统的计算负荷分布到云端进行,将结果发送至车载模块,实现车路协同[13]。建立城市环境下场外停车诱导系统的V2R 通信模型,如图1 所示。具体通信步骤如下:

图1 V2R 通信架构
1)在每个更新周期T内,每个停车场节点将自身停车信息(停车位占用情况、排队信息等)、位置等发送给RSU,实现信息的实时传递与更新。
2)当车辆有停车需求时,向RSU 发送自己的预订停车时长与行驶目的地,由RSU 进行存储和计算。
3)RSU 执行停车诱导策略算法,对时间步内有停车需求的车辆进行统一调度,并将调度结果返回给车辆。
4)各车辆分别前往由RSU 提供的停车场,完成停车诱导。
5)RSU 将诱导结果发送给停车场P,P根据诱导信息更新自身状态。再重新执行步骤1)。
1.2 预测模型
假定在某道路交通系统中,在时刻t行驶着N辆汽车,这些汽车构成了交通系统中的车辆集合V={V1,V2,···,VN},区域内包含M个停车场,构成停车场集合P={P1,P2,···,PM},对应于每一个停车场Pj假定有mj个停车位。
某时刻车辆Vi发起停车预订请求,包含停车时长Ti,以及行驶目的地Di,构成一个预订信息表G=〈T,D〉。该车辆需要寻找合适的停车场进行停车,对于 ∀i=1,2,···,N:

将状态改变1 次的时长设为1 个时间步,根据车辆所在位置 (xi,yi),停车场所在位置 (xj,yj),考虑停车场的车位占用情况,∀j=1,2,···,M,为车辆选择停车场制定一个策略F=Fi j:

在车辆发起停车预订请求以及成功停车时对Vi和Fij的值进行更新。并且,对它们施加一个约束:

即可得到停车场Pj的服务量pj:

式中p0为实时获取的停车场当前服务量。
由于车辆到达各个停车场的距离不同,即车辆在路途中消耗的时间各不相同,这会导致车辆到达停车场进行排队的顺序不同。设车辆Vi到达停车场Pj的路程为di,j,行驶的平均速度为vi,则路途耗时为

对于场外停车诱导策略来说,车辆的排队时间很大程度上由排队长度决定。假设停车场Pj的当前排队车辆数目为L,车辆的排队位置为

式中:lP为正在停车场处排队的车辆长度,lT为在去往停车场过程中所用时间较小的排队车辆长度。对于l∈{1,2,···,L},停车场Pj的当前排队队列中第l辆车表示为Vl,j,uj表示在停车场Pj中当前被占用的停车位数量,tinit为车辆发起停车需求的起始时间,βl,j为Vl,j停车结束时间。车辆停车消耗的总时间T包括路程时间和排队等待时间,设车辆在停车场预订的停留时间=Ti,分3 种情况对停车结束时间 βl,j进行讨论:
1) 当uj+l≤mj时,即停车位充足,没有车辆进行排队时:

2) 当l=1且uj+l>mj时,即当前车辆位于排队位置的第一个时:

3) 当l>1且uj+l>mj时:
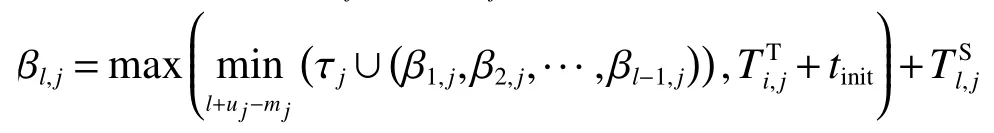
式中:τj为当前占用停车位的车辆的结束停车时间集合,为时间集合中第l个停车结束的车辆离开的时间。
所以车辆Vi去往停车场Pj停车消耗的总时间为

则系统内车辆完成停车所消耗的平均停车总时间为

2.1 MDP 下的停车诱导模型
本文采用马尔科夫决策过程(Markov decision processes,MDP),基本框架如图2 所示。设置停车诱导系统为一个智能体,在执行停车诱导策略时,系统与环境进行交互,环境通过一组状态和动作进行建模,在动作和环境的作用下,系统会产生新的状态,同时环境会给出一个奖励。系统以这样的方式不断循环,智能体与环境不断交互,则会产生许多数据。

图2 MDP 的基本框架
强化学习方法是根据系统反馈的奖励修改自身动作,再通过环境交互获得新的数据,从而进一步改善自身的行为,最终智能体在不断的学习过程中逐步完成最优策略的制定。
2.1.1 状态空间S
对于一个状态空间S,有st∈S。在本文中,设st=Kt,Kt为在时间步t时M个停车场的空闲位置,。场外停车诱导系统在每个状态st下采取不同的动作,则诱导情况会处于不同的状态。将用户车辆调度到不同的停车场的到达时间是多种多样的,并且当有一辆新的车辆到达指定停车场,或者有已完成停车任务的车辆离开时,都可能发生状态转换。所以在不同的调度动作下会产生不同的下一状态。
2.1.2 动作空间A
动作at∈A,是场外停车诱导决策。在状态st下,各车辆选择一个在距目的地的里程约束下可以到达的停车场进行停车,即为诱导决策动作。每个发起的停车需求会造成系统状态的改变,而各车辆在最优决策下做出的动作也会改变系统的状态。设置动作空间为每个车辆Vi(i∈[1,N])做出的对于停车场的选择ai={Vi,P1,P2,···,PM},其中:

为该策略添加约束,以保证策略的完备性以及唯一性,即保证系统内车辆总数限制为N:
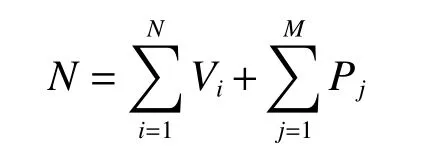
2.1.3 状态转移函数
在停车诱导系统中,每一个状态下做出的实时动作决策都会对当前状态产生定向的改变,但在未来的停车诱导中,当前的最优决策可能不会产生未来的最优决策。所以系统需要估计未来的回报,以获得对当前决策的评价。
在本文中,存在2 类主要的动态因素,即完成停车任务所消耗的总时间以及到达目的地的总路程。消耗的总时间较短且总路程较小的车辆所做出的动作被认为是更优的,系统则会为这些动作分配更高的执行概率,以使决策向着更优的方向发展。因此设计一个状态转移函数T(s,a,s′)[14],在MDP 条件下的下一状态不受历史动作和状态影响,只受当前状态的影响,即

在状态s下执行动作a,系统会以均匀分布的形式提供状态转移概率,将停车场的当前占有率转移到下一状态s′。并且,对于每个动作a,以及每个状态s,都需要满足 0 ≤T(s,a,s′)≤1。
2.1.4 奖励函数R
车辆执行动作an∈A,然后前往指定的停车场进行停车,学习器将从该车辆的策略中获得奖励。系统通过奖励函数对决策结果进行反馈,以实现学习和更新。考虑车辆停车过程所消耗的总时间,以及从发起停车请求的起始点到目的地的路程,目标是在满足约束条件的同时,将车辆消耗的总时间降至最低,并最大程度地缩短行驶路程。所以本文中,设置奖励函数为

式中:T(st,at)为车辆在状态st下做出动作at所消耗的停车总时间;
为初始行驶里程;
为与初始里程相比减少的距离;
α 和 β分别代表消耗时间和距离所占的权重,若 α较大则策略更倾向于选择所用时间较短的停车场进行停车,反之则更倾向于选择行驶路程较短的停车场进行停车。
2.2 基于Q-learning 的停车诱导策略
基于Q-learning 的场外停车诱导策略需要确定一个策略 π,定义为在时间步t对所有发出停车请求的车辆所作出的一系列停车调度动作at,所以π=(a1,a2,···,at)。我们的目标是得到一个策略π*能最大化总奖励:

式中Qπ(st,at)为长期回报状态-动作值函数:

式中:τ为根据停车诱导策略和状态转移通过采样所获得的序列,γ ∈(0,1]为折扣因子。
当状态st下做出最佳动作动作at,则能够得到最优状态-动作值函数Q*(st,at)为最大期望回报。
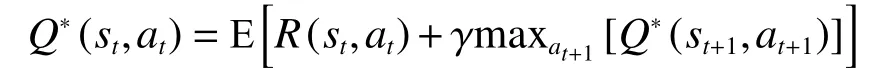
采用Q-learning 的停车诱导算法流程如下:
1)初始化参数,对于 ∀s∈S,∀a∈A,价值函数Q(s,a)=0。
2)更新系统环境状态s,当受到来自车辆的预订信息时,执行停车诱导策略。
3)基于Q值,选择并执行动作a∈A。
4)观测新的状态s′,并得到奖励函数R(s,a),更新Q值为

5)执行策略最优策略 π*为
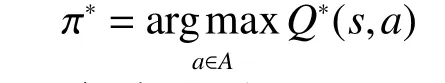
6)s←s′,重复步骤2)。
在本节中,基于One 仿真平台进行模型搭建,在模型下应用本文算法,完成基于强化学习的场外停车诱导策略(RL),并将其与基于最短步行路程(minimum distance,MD)[15]策略、基于最短排队时间(minimum queue time,MQT)[16]策略、基于预约(reservation based,RES)[17]策略进行比较,从总路程、平均消耗时间、累积停靠数以及停车场占用率方面对算法性能进行有效的评估。
3.1 模型搭建
如图3 所示,本文在One 仿真平台上将哈尔滨市部分地图作为仿真背景,部署了150~400 辆车、7 个停车场和6 个RSU。设置仿真时间为12 h,停车场车位数量选取为30~60 个,场景内车辆移动速度为30~50 km/h,车辆在距离目的地小于2 km时会发起停车请求,并且参数 α 和 β的设置考虑了实际生活中用户的偏好。

图3 场外停车诱导场景
3.2 实验评估
3.2.1 停车总路程评估
使用Dijkstra[18]算法计算开放街道地图(open street map,OSM)道路网络中的最短导航距离,包括发起停车需求的位置到停车场的行驶距离,以及2 段停车场到预订目的地间的步行距离。
由于MD 策略是选择距离目的地最近的停车场进行停车,故不考虑对MD 策略下的停车总路程进行评估。由图4 可知,随着车辆的增加,车辆的平均总行驶里程略有增加。MQT 策略只考虑排队等待时间,所以当车辆越来越多时,会选择距目的地较远的停车场进行停车。而RES 策略下,车辆对停车场进行预约,则可以避免某些车辆停车过远,但由于受用户主观动作影响,所以无法达到最优决策。而RL 策略下的车辆考虑路程因素,智能选择停车场,所以性能表现最好。
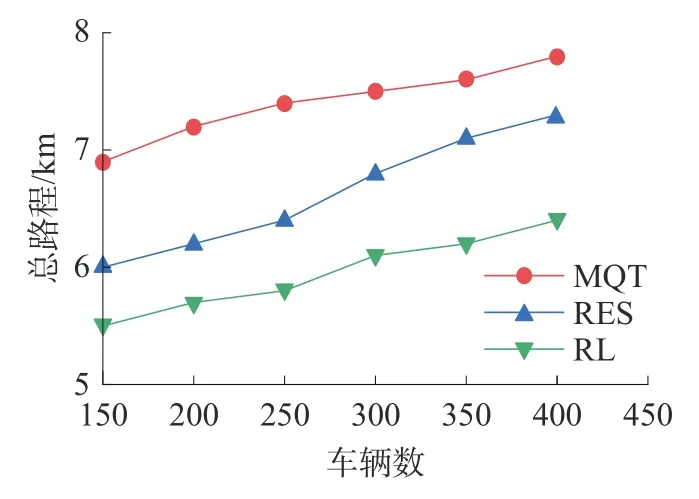
图4 不同车辆数下的平均总路程
3.2.2 停车总时间评估
如图5 所示,当场景内车辆数较少时,空闲车位数量可以满足停车需求,所以排队等待时间对停车总时间的影响较小,而车辆行驶路程消耗的时间则占了更大的权重,此时MD 策略下车辆选择距离自己最近的停车场进行停车,所以所消耗的总时间也就最短。但当车辆数不断增大,停车规模超过停车场所能承担的负荷时,MD 策略下就近选择的方式会使车辆集中涌入某几个停车场而造成停车负载不均衡,产生停车排队等待时间,停车消耗的总时间也就明显增加。MQT 策略考虑了车辆排队等待时间而忽视了路程时间,所以性能略有提升。RES 策略由于对车位进行了提前预约,所以车辆越多时该策略优势越明显。而本文采用的RL 策略考虑路程时间的同时,平衡各停车场的占用率,极大地减少停车需求规模对策略性能的影响,所以随着车辆的增加,该策略性能优势逐渐增大。

图5 不同车辆数下的平均消耗时间
3.2.3 累积停靠数评估
本次实验部署了400 辆汽车,由图6 可知,在12 h 内,停车场完成的累积停靠数逐渐增加,并最终趋于平稳。由于车辆规模较大,所以空闲车位数量无法满足停车需求,这时各停车场的停车占用率是否平衡对性能影响较大。

图6 累积停靠数
MD 策略只考虑了路程因素,选择距离目的地最近的停车场进行停车,会导致城市中心停车场负载过大,停车效率低,所以性能表现最差。MQT策略考虑排队等待时间,在一定程度上能够解决车辆分配的问题,但随着时间的增加,在距目的地距离的约束下,仍会有停车场车辆趋于饱和,所以最终停靠数没有明显提高。而采用预订机制的RES 和RL 策略能够明显地缓解单一停车场过饱和的趋势,在强化学习的作用下,RL 策略则能更好提高系统停车效率。
3.2.4 停车场占用率评估
由于MD 策略采取就近原则,只选取距离目的地最近的停车场进行停车,并不能起到平衡停车场占用率的作用,所以在本次实验中不作考虑。而MQT、RES 和RL 策略都能在一定程度上平衡停车场的停车占用率,所以按距离目的地由近到远的顺序依次选取3 个停车场,在场景内有400 辆汽车时,对MQT 策略、RES 策略和RL 策略的性能进行进一步比较。
图7 显示的是12 h 仿真结束后3 个停车场的停车占用率情况。
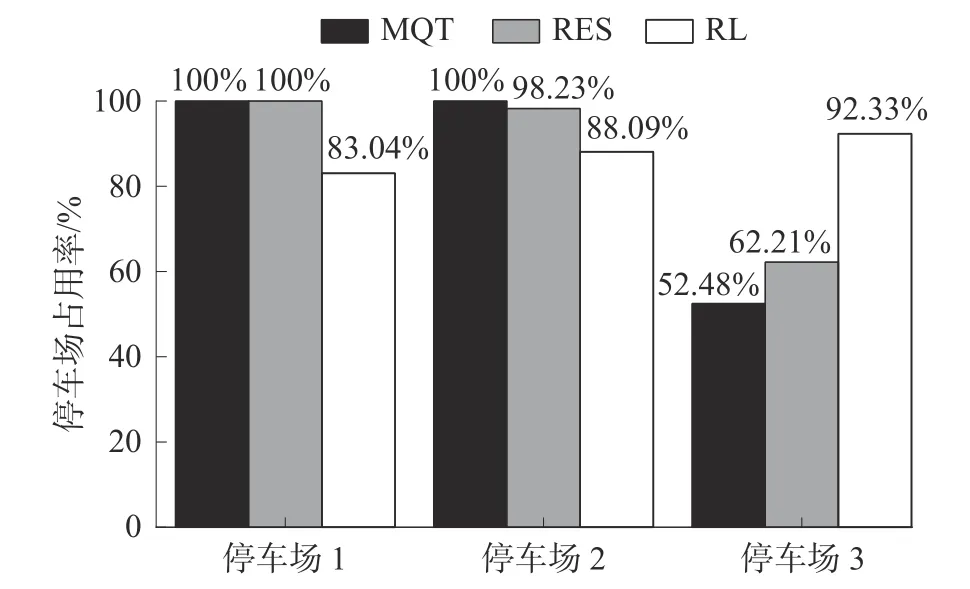
图7 12 h 后的停车场占用率
可以看到,在MQT 策略中,较近的停车场1 和停车场2 的占用率已达到100%,而停车场3 的占用率只有52%,所以该策略平衡占用率的效果较差。在RES 策略下,3 个停车场的占用率分别为100%、98%和62%,停车场1 和停车场2几乎已满,而停车场3 仅使用了2/3 的停车位,这说明采用用户主导的预约方式仍不能很好地平衡停车场的占用率,用户更倾向于选择距离目的地较近的停车场进行停车。但在RL 策略下,3 个停车场的占用率在83%~93%,达到了很好的平衡效果。
1)本文在构建停车信息预测模型时,摒弃对停车可用性概率的预测,采用停车预订的方式对停车时长及旅行目的地进行预设,能够在一定程度上解决未来停车信息的不确定性,是实现停车诱导策略的前提。
2)结合强化学习方法,对多目标进行处理,以智能化的方式解决停车诱导问题。经与其他策略对比发现,改进的基于强化学习的场外停车诱导策略在停车总路程、平均消耗时间和累积停靠数方面都具有明显的优势,并且平衡了停车场的占用率,从全局角度优化了停车诱导策略。
3)采用的停车预订机制虽然能够很好地解决对未来停车信息预测的问题,但在特殊事件的影响下依然会有所偏差,所以如何能够更准确地对未来的空闲停车位数量进行预测,是需要解决的重要问题。
猜你喜欢 占用率路程停车场 1090 MHz信道分析软件设计与实现计算机工程与设计(2022年3期)2022-03-22求最短路程勿忘勾股定理中学生数理化·七年级数学人教版(2022年3期)2022-03-16Maxe 迷宫闯一闯阅读(快乐英语高年级)(2020年6期)2020-08-28多走的路程数学小灵通·3-4年级(2020年6期)2020-06-24适当提高“两金”占用率助人助己企业文化(2020年8期)2020-06-03停车场迷宫数学大王·低年级(2019年12期)2019-08-14降低CE设备子接口占用率的研究与应用魅力中国(2019年6期)2019-07-21多种方法求路程小学生学习指导(高年级)(2019年6期)2019-01-11走的路程短发明与创新·小学生(2018年12期)2018-12-29停车场寻车管理系统电子制作(2018年9期)2018-08-04本文来源:http://www.zhangdahai.com/shiyongfanwen/qitafanwen/2023/0720/627995.html



