【www.zhangdahai.com--其他范文】
俞祥基,蒲俊良,周 川,张隆春,唐 林,陈巧灵
(成都深思科技有限公司,四川 成都 610095)
近年来,随着互联网技术的不断发展,网络数据安全也愈加被人们所重视,许多行业领域都需要对网关出口的流量数据进行嗅探捕获,并针对其进行流量审计,从而确保数据安全。在审计过程中,都会采用传输控制协议(Transport Control Protocol,TCP)流重组技术,只有将TCP流数据报文重组以后,才能还原完整的TCP会话,从而获取TCP传输的真实内容,用于流量审计。当在网络中使用TCP协议进行数据传输时,需要将完整的数据内容拆分成多个数据报文进行传输。由于网络环境的复杂性较高,比如网络设备参差不齐、信号传输过程存在衰减和干扰等,经常会导致TCP数据报文乱序或丢包重传等,因此嗅探重组TCP流就需要考虑TCP数据报文的乱序、重叠、丢包、重传等许多复杂情况。而现有的TCP流重组技术大都存在效率低下、重组不完整、程序内存占用过高等问题。
本文针对上述情况,研究了TCP流重组技术,旨在提供一种稳定且准确、高效且快速的TCP流重组技术,为后续的网络数据安全审计提供有力的技术支撑。该技术具有一定的工程应用价值。
TCP是目前Internet中广泛采用的一种传输协议,是一种面向连接的、可靠的、基于字节流的通信协议,它为各个主机之间提供可靠、按序传输、端到端的数据包传输服务。TCP协议发出的每一个数据包都要求确认,其中如果有一个数据包丢失就收不到确认,发送方就必须重发这个数据包。为了保证传输的可靠性,TCP协议建立了3次对话的确认机制,即必须先与对方建立可靠连接才能正式发送数据。TCP的数据包没有长度限制,理论上可以无限长,但为了保证网络效率,通常都会将TCP数据包依照TCP/IP模型中传输数据时所能使用的最大传输单元(Maximum Transmission Unit,MTU)进行分片,以太网的MTU默认是1 500,即一个TCP数据报文默认长度均为1 500。由于TCP协议具有重发与分片特点,结合网络空间的延时、信号衰减等实际情况,导致现有TCP流分片重组技术实际的局限性。
早期的分片重组技术主要通过高性能的硬件堆高计算性能,从而实现高速的TCP流重组,但在目前网络流量呈指数级增长的情况下,再通过独立的高性能硬件达到TCP重组性能要求,成本实在过于高昂且低效。目前主流的分片重组技术研究,大多是考虑硬件与软件相结合,以及提高软件算法在TCP流重组技术中的占比,主要应用在为CPU减负、流量重组、提高重组效率等场景。
2012年,王文豪[1]等人提出了一种基于现场可编程逻辑阵列(Field Programmable Gate Array,FPGA)的IP分片重组技术,目标是减轻CPU负担,提高重组效率。文中采用中央地址存储器(Central Address Memory,CAM)来设计和担当IP分片重组的信息识别核心模块,并追加片外大容量随机动态存储器来实现IP分片的数据缓存,最终实现IP分片报文的快速识别及有效重组。该技术可以应用于乱序、重复等异常场景,其处理数据的效率为1 Gbit/s以上。使用CAM作为运算核心,虽然具有查找速度快的优点,但是其硬件资源消耗很高,无法持续支撑大数量的IP分片信息存储、查询等,在持续运行大数量IP分片重组时,会导致系统的资源紧张,进而影响处理能力,造成IP分片重组失败,甚至系统崩溃。
2014年,窦衍旭[2]提出了一种基于哈希表对高速网络中的IP分片进行重组的技术,主要用于高速网络中的流量嗅探还原。该文中先将由源IP地址、源端口、目的IP地址、目的端口组成的4元组作为关键字构建了具有高速查询效率的哈希表,并通过TCP超时检测机制提升了哈希表查询的稳定性及效率性,实现了IP分片的快速查询管理,再进行具体的流重组操作,最终实现了1 Gbit/s流量下的IP分片重组。然而,由于没有对网络环境中存在的丢包重发情况进行深入研究处理,其重组的准确率受到严重影响,只有68%。
2016年,刘贤熜[3]采用了一种MapReduce编程模式的并行结构对流量进行分析和统计,对TCP报文按照关键4元组信息完成辅助排序与分类,再基于Hadoop进行数据报文的大量并行处理。该文中利用滑动窗口来寻找相邻两个数据包的时间戳,实现数据报文的定位及分割;
利用分布式设备不受单机设备计算瓶颈影响的特点,实现TCP数据包的高效重组。
2016年,许青林[4]通过基于三维立体空间的重组算法优化重组流程,引入多级双循环缓冲队列提高重组效率,并利用自适应动态哈希内存池进行缓存映射,去除数据报文在排序重组过程中的多次拷贝转移过程,最终实现了900 Mbit/s流量的TCP报文重组。
2018年,赵勇[5]提出了结合Hash表的分段管理与伸展树算法的TCP流排序重组算法。该文优化了分片排序重组过程中5元组的快速查找性能,并结合TCP状态机的约简策略,迅速地将数据报文的重组速率提升到了2 Gbit/s,但其在面对并发数量多、分片数量多的场景时,性能快速下降。利用TCP状态机的研究还有2019年由程子帅[6]提出的并行TCP双向数据流重组技术,其通过优化TCP状态机生成TCP的值,适用于数据报文乱序、重发等异常情况下的TCP报文重组。
2020年,黄锐[7]提出了一种基于FPGA实现的TCP乱序报文重组办法,利用硬件实现底层TCP/IP协议栈,解放了CPU的计算性能,可以解决网络中网络堵塞或传输误码造成的数据报文丢失,多路由转发导致的数据报文乱序等异常情况。文中充分利用硬件特点来记录数据报文的偏移信息,在缓存中比较排序重组。该方法资源占用低且非常有效,但同样受限于硬件特点,最大只能支持3个分段的数据并发重组,无法用于并发重组数量较多的场景。
综上所述,目前主流的分片重组技术已经较为成熟,但是其技术特性都不够全面,无法满足高速率、复杂场景下的高并发需求,因此TCP分片重组技术仍然具有一定的改进空间。
平衡树(Balance Tree,BT)算法指的是在一棵树中,其任意节点的子树的高度差都小于或等于1。平衡树由2-3树改造而来,它的时间复杂度和空间复杂度都比2-3树要低,并在实现对集合的并、交、差等系列操作时可以始终保持平衡,提升存储空间的利用率。
2.1 现有拓展算法
2.1.1 二叉平衡搜索树
二叉平衡树,又称为AVL树,是符合平衡树特征的一种特殊的二叉排序树。它可以是空树,当不是空树时,每一个节点的左右两子树都是平衡二叉树,且子树高度之差的绝对值不超过1。
二叉排序树支持快速地插入、删除、查找操作,各个操作的完成时间都在O(logn)以内,O(logn)也称为时间复杂度,其中,O是和树的高度成正比的。但是,在频繁的插入、查询过程中,二叉排序树不断更新,可能会出现树的高度远大于logn的情况,导致树退化成链表,时间复杂度也变成了O(n)。为了避免这种复杂度退化的问题,二叉平衡树被提出。二叉平衡树让树尽量保持左右平衡,提升插入、查找、删除的效率,并引入节点平衡因子(Balance Factor,BF),使得左子树的高度减去右子树的高度的绝对值小于等于1。图1给出了一个平衡的二叉平衡树的示例。

图1 二叉平衡树
二叉平衡树在插入或者删除节点时,可能打破树的平衡,而通过左旋与右旋两种选择操作,就可以使树恢复平衡。例如插入一个新节点到根节点的左子树的左子树,导致根节点的平衡因子变成2,就可以进行右旋操作使树恢复平衡,如图2所示。

图2 二叉平衡树右旋
通过左、右两种基本旋转的互相组合,结合递归算法的思想,不断重复进行左旋或右旋,最终即可尽量保持二叉平衡树的平衡结构[8]。
2.1.2 多路平衡搜索树
从上文介绍的二叉平衡树的内容可以看出,二叉平衡树每一个节点最多只能保存一个关键字和两个子节点,在维护过程中还会进行大量的磁盘寻址和读写操作。为了在同一个节点内能够存储更多的信息,减少磁盘寻址的次数,增强数据的查询性能,多路平衡搜索树被提出。它突破了二叉平衡树每个节点只能保存1个关键字和2个子节点的限制,并引出了如2-3树、2-3-4树、B树等多种多路平衡搜索树[9]。
B树是多路平衡搜索树中最为典型的一种,它的操作时间复杂度同为O(logn)。一棵B树有以下性质:
(1)根节点中最多有m棵子树,有x(0≤x≤m)棵子树Pi(1≤i≤m)和m-1个关键字Ki(1≤i≤m);
(2)一个节点中的所有关键字Ki(1≤i≤m),满足Ki<Ki+1,子树Pi中的所有关键字都大于Ki-1,小于Ki;
(3)根节点至少有一个关键字及两个子节点,除根结点外的所有非终端结点至少有m/2棵子树;
(4)所有内部节点至少有t个子节点,最多有2t个子节点,至少有t-1个关键字,最多有2t-1个关键字;
(5)所有的叶子节点都在同一层,子叶节点不包含任何信息。
图3给出了一棵3阶B树的示例。

图3 3阶B树
在B树的实际操作中,对于叶节点已经写满的情况,引入了分裂操作,它可以将该叶节点分裂,把中间的关键字升至父节点的正确位置,保证B树的插入操作不会导致B树不合法,如图4所示。此外,删除操作也引入了向上回溯来保证B树对于结点的关键字数量的限制。

图4 B树插入分裂
2.2 拓展区间管理算法
多路平衡搜索树的一个重要思想是扩展了二叉平衡树1个节点只能保存1个关键字和2个子节点的概念。根据这个思想,本文尝试将这个概念再次进行扩展,提出了区间管理算法。将TCP流报文中元素的动态集合,即报文分片,作为要保存的关键信息,在平衡树基础上进行扩展得到支持以区间为元素的动态集合的操作,其中每个节点的关键值是区间的左端点。通过建立这种特定的结构,使区间元素的查找和插入都可以在O(logn)的时间内完成,该算法的具体流程如图5所示。

图5 区间管理算法
每一个节点代表一个报文,节点区间的左右值分别为报文的序列号(seq)和序列号+当前报文长度(len)-1,比如数据报文seq为1,len为100,此数据报文对应的节点的区间为[1,100]。
区间管理算法和TCP协议自身的确认应答机制(Acknowledge character,ACK)非常搭配。ACK包确认机制是对接收到的数据进行确认,在发送端一次性发送多个数据报文时,如201、301、401的数据报文,不必等到接收端的一一确认,只需要知道401的确认报文,即可认为201、301、401报文都接收到了。序列号包确认机制是当发送端一次性发生多个数据报文时,如201、301的数据报文,接收端的ACK暂未到来,若201数据报文的序列号加上当前报文长度等于301数据报文的序列号,则可以判断301即为201后面连续的包。通过将ACK机制确认后的TCP分片报文直接作为区间管理算法节点中的保存数据,可以大幅提升数据的查询效率,尤其针对乱序、丢包等异常的TCP流分片。
3.1 TCP流量采集与预处理
本文主要研究的是TCP流的重组技术,但通过网络出口直接嗅探到的流量报文是不能直接投入流重组系统中的。因此,需要从网络出口尽量获取高完整性、高可靠性的流量,快速准确地分离出其中的TCP流报文,并将需要重组的报文进行高效的筛选缓存,排除其中无效和重复的报文,再投入流重组系统中进行TCP流重组,最终输出重组后完整的TCP报文。
3.1.1 TCP流采集
在网络空间中,如流量分析、网络状态分析等很多功能都依赖于获取的网络基础流量,因此网络流量采集技术一直在不断发展,从以前的基于侦听网络数据包的采集技术、基于网络探针的流量采集技术、基于PF_ING框架的高性能数据包流量监测及处理技术,到近些年流行的基于数据平面开发套件(Data Plane Development Kit,DPDK)框架的高速流量采集技术,高效获取网络空间流量不再是难以达到的目标。
基于侦听网络数据包的数据包采集技术[10]具体是通过将网卡模式设置为“混杂”模式,使得处于共享介质网络上的任何流经该网卡的数据包都可以被侦听到,但该模式难以保证侦听数据的完整性。
基于网络探针的流量采集技术利用了Ethernet总线结构的思想,以IP为单位,将网络监听程序安装到待监听设备上,详细记录该设备的每一次的通信,再根据IP进行数据汇总统计,但此方法对流量统计的核心设备要求极高,需要有足够的缓存空间和运算速度,不适用于本文场景。
基于PF_RING框架的高性能数据包流量监测和处理技术,其核心概念是通过直接内存访问(Direct Memory Access,DMA)将流经网卡的网络流量作为对象,直接映射进用户空间,跳过繁琐的网卡到内核、内核到用户空间的方式,节约CPU处理时间及压缩数据拷贝次数。PF_RING技术实现的新式SOCKET连接,可以直接实现应用程序与PF_RING内核的通信,即可以通过PF_RING句柄完成数据包的直接读取,不存在对每个数据包的内存分配释放动作。但要实现最大性能的数据包抓取,PF_RING技术需要对网卡驱动进行定制化重写,实现难度较大。
2022年由邓金祥[11]提出的基于DPDK框架的高速流量采集技术,通过DPDK平台中的大页内存方式提高内存访问效率,并采用零拷贝技术降低了数据报文在处理过程中的流转消耗,优化了数据报文从内核态到用户态的处理流程带来的大量性能消耗,实现了大流量场景下的流量还原及采集。本文通过该技术实现了高完整性、高可靠性的网络流量采集,并为后续的TCP流重组过程预留足够的性能资源。
3.1.2 TCP流量预处理
如图6所示,对还原TCP流的前期预处理,本文首先采用了通信数据校验中常用的循环冗余校验码(Cyclic Redundancy Check,CRC)[12]对数据报文进行快速校验,排除其中的错误及重复报文;
其次对分片数据帧进行内容解析,快速排查ACK及序列号(Sequence Number,SEQ)的值,保留需要重组的数据帧分片,不需要重组的数据报文直接输出至存储单元;
最后采用Hash索引算法对TCP数据报文的分片帧进行快速索引计算,并建立Hash列表,用于后续重组流程。

图6 报文处理流程
CRC利用了除法及余数原理来进行传输错误侦测,其在数据发送前,对待发送数据n进行计算并得出一个冗余位k(校验帧);
然后将k添加到n后,形成新的待发送数据帧T;
发送后接收方获得数据帧T,采用相同的计算方式,对n进行计算,如果k相同则传输正确,反之则传输错误。CRC的检错能力十分出色,目前它发现错误的概率在99.99%以上,且其资源消耗小。常用的CRC计算多项式如表1所示。TCP数据报文中的校验帧为4位,按照TCP/IP协议标准,本文可以确定使用的是CRC-32。

表1 常见CRC多项表达式
Hash索引算法是基于待查询数据利用Hash函数计算出一个Hash值,并将其构建为一个Hash列表,在需要数据查询时,直接使用列表中的Hash值作为查询地址进行查询,实现了数据的快速读写操作。Hash函数又被称为散列函数,它通过某种确定性的算法将输入按照算法转变为输出,相同的数据输入永远可以得到相同的数据输出,而即使极其细微的偏差也会导致输出的不同。常见的Hash算法包括直接寻址法、除留余数法、位运算法、伪随机数法等。
在Hash索引实现的过程中,由于输入数据的值域特点不同,出现了Hash运算后Hash值相同的情况,即Hash冲突,这会使得不同的分片帧的存储地址相同,从而出现存储信息覆盖、丢失等问题,最终导致数据报文无法按正确顺序进行重组。解决Hash冲突的常用办法有如下4种:
(1)链地址法:为每个Hash值建立一个单向链表,对于相同的Hash值,将其加入对应的链表中。
(2)再Hash法:Hash函数的计算方式多样,如果第1个计算方式得出的key值冲突,就轮换使用第2个计算方式,直到无Hash冲突产生。
(3)开发寻址法:当对应的Hash值的存储地址P产生冲突时,以P为基础,向上或者向下,找到一个未存储数据的可用实际地址P1来进行数据存储,若已存储数据则跳过该地址。
(4)建立公共溢出区:将整个Hash列表分为基础表和溢出表两部分,凡是和基础表发生冲突的元素,都填入溢出表中。
3.2 TCP流重组流程设计
如图1所示,TCP流重组设计实现了将分片数据帧重组为完整的原始TCP报文的功能,这是本课题研究的核心重点。该TCP流重组设计完成了分片数据帧的排序、缓存、重组等处理,详细的重组流程如下文所述。
步骤1:接收TCP报文,按4元组计算session hash值,从缓存中取出session相关信息,如为空,则新建session相关结构。
步骤2:判断确认队列是否为空,为空则将报文直接放进确认队列、更新区间树、记录报文传输方向和next seq,返回步骤1;
不为空,则执行步骤3。
步骤3:根据4元组判断报文传输方向,如与上一条报文方向一致,则执行步骤5;
不一致,则执行步骤4。
步骤4:判断当前报文ACK是否等于上一报文next seq,等于则表示两报文为连续报文,将报文放入确认队列,更新区间树,并记录报文传输方向和next seq,否则执行步骤6。
步骤5:判断当前报文seq是否等于上一报文next seq,等于则表示两报文为连续报文,将当前报文放入确认队列,更新区间树,并记录报文传输方向和next seq,否则执行步骤6。
步骤6:计算当前报文的区间值,从区间树中查询此区间值;
如果查到,则表示当前报文为重复报文,丢弃即可;
如未查到,则表示当前报文为乱序报文,放入待确认队列,执行步骤7。
步骤7:当待确认队列中报文数量大于n,有n个报文堆积待重组时,如果n大于5,很可能传输过程中有丢包行为,从而产生数据空洞,导致后续报文不能确认。这时应从待确认报文队列中取出报文无视空洞,按后续顺序强制加入确认队列。
步骤8:当前TCP报文重组结束,继续返回执行步骤1。
新设计的TCP流重组流程,通过优化程序步骤,引入分片数据帧预处理机制和Hash索引算法,解决了传统TCP流重组方式因乱序报文查询效率过低导致重组效率低,不能满足大流量环境下的TCP流重组,以及重组完整度不足的问题。

图7 TCP流报文重组流程
本文利用区间管理算法实现的TCP流重组技术的核心目的在于支持数据完整、有序地完成重组工作,且重组效率得到大幅度提升。为测试报文重组的正确性及重组效率,构建了由4台万兆级别数据包发送服务器、1部万兆路由器、1台基于本文所提技术的万兆数据采集及重组服务器组成的测试环境。4台万兆级数据包发送服务器将通过控制最大传输单元(Maximum Transmission Unit,MTU)来模拟实际真实网络的无序状态。
4.1 区间管理算法重组TCP流的正确性测试
本节对利用区间管理算法的TCP流重组技术进行正确性测试,首先选择1台数据包发送服务器,使用文件传输协议(File Transfer Protocol,FTP)向另一台目标数据包发送服务器传输1个大小为4.82 MB的压缩文件test.rar,并在目标数据包发送服务器上使用TcpDump进行抓包;
其次使用区间管理算法的TCP流重组技术对抓到的数据包进行报文重组;
最后分别计算发送前的test.rar文件MD5值和重组得到文件的MD5值。重组结果及MD5验证结果如图8所示,两个文件的大小、MD5值均相等,说明重组文件的结果是正确的。
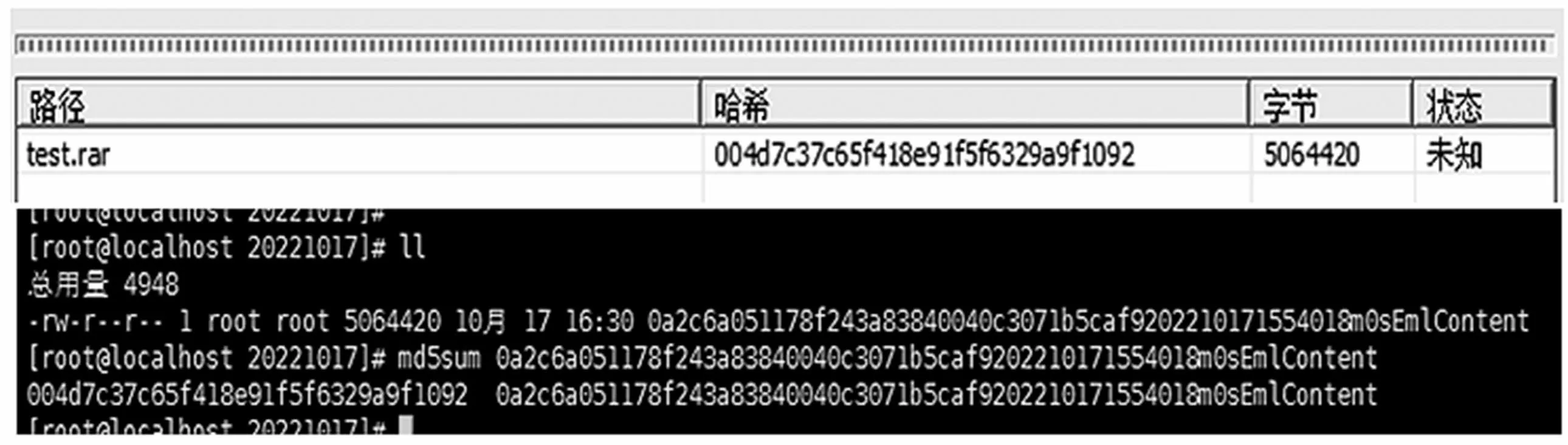
图8 文件重组及MD5结果验证
4.2 区间管理算法重组TCP流的性能测试
本节对利用区间管理算法的TCP流重组技术的性能进行测试。该次测试主要关注在不断增长的网络流量下,TCP流重组技术是否能正常稳定运行。测试其每秒处理数据包(Packets Per Second,PPS)、设备内存使用情况和流量重组准确率3个方面的性能。流量发送方面,由4台万兆级别数据包发送服务器平均分配TCP数据流进行发送,发送速率依次为250 MB/s、500 MB/s、1.25 GB/s、2 GB/s和2.5 GB/s,构造出在路由器网络节点处的网络流量总量依次为1 GB/s、2 GB/s、5 GB/s、8 GB/s、10 GB/s的网络流量环境。4台数据包发送服务器的MTU值依次设为256,512,1 024和1 500字节,用于模拟真实网络环境的乱序现象。将路由器的网络流量旁路接入利用了本文区间管理算法重组技术的万兆数据采集及重组服务器,对上述3个性能参数进行监测,其结果如图9所示。
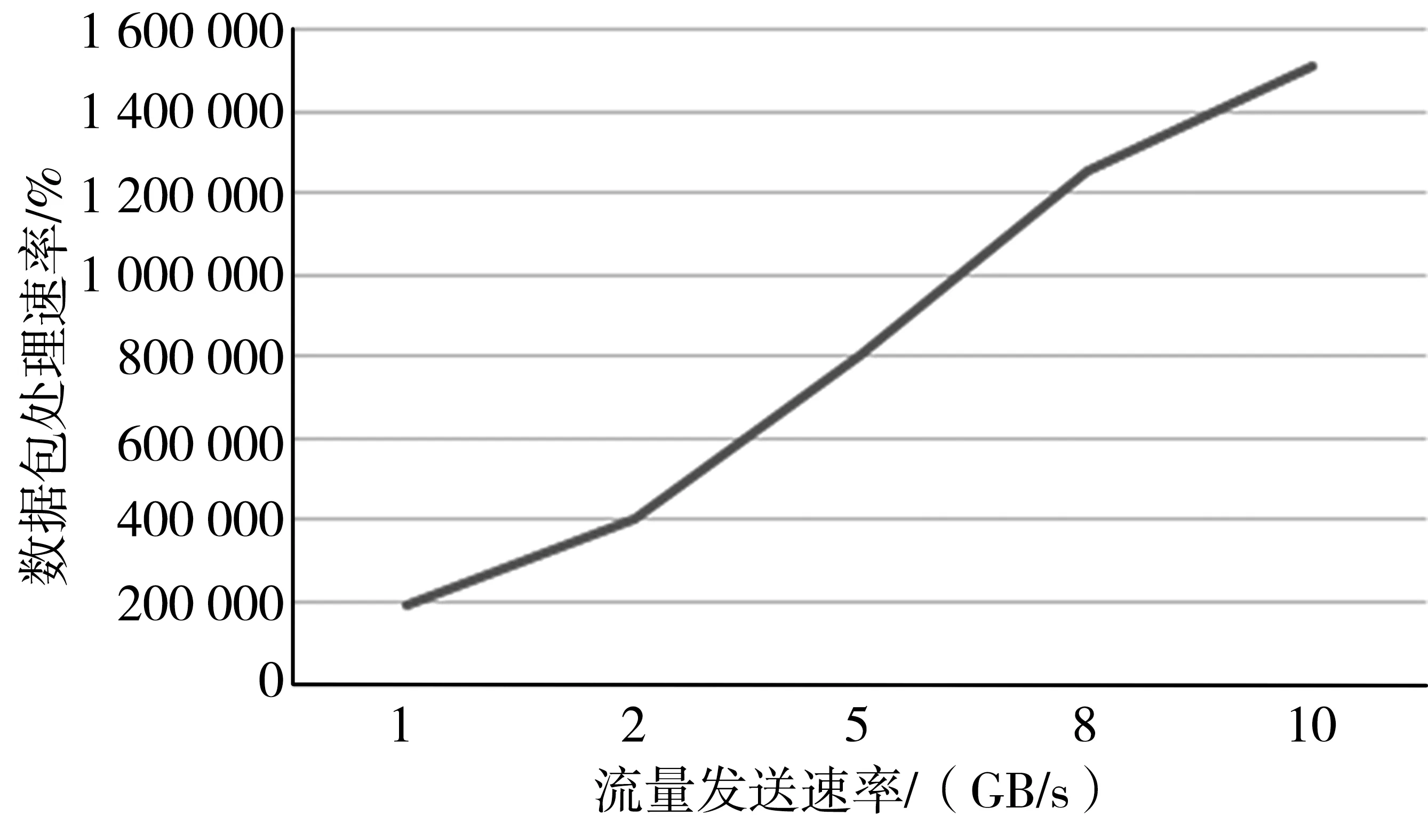
图9 不同流量下每秒处理的数据包
综合上述测试数据,可以看出采用区间管理算法的TCP流重组技术在准确性上有着显著的性能优势。如图9、图10和图11所示,随着网络流量的提高,重组准确性并没有下降太多,而PPS和内存使用情况都随着网络流量的增加呈线性增长,且暂时没有出现算法程序上的瓶颈。至于在更大网络流量下的运行情况,受限于硬件条件,本次没有进行相应测试。此外,每一个层级的网络流量重组场景都运行了至少4个小时,也证明了利用区间管理算法的TCP流重组技术的稳定性。
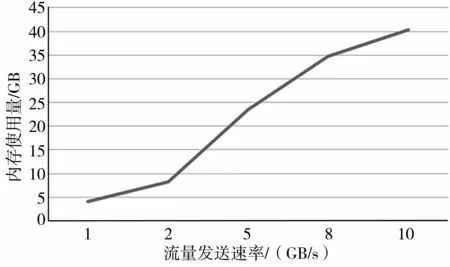
图10 不同流量下内存使用情况

图11 不同流量下流量重组准确率
毫无疑问,对比前文所述的各项分片重组技术,本文所研究的利用区间管理算法的TCP流重组技术在性能上有着不小的优势。
在现在网络加速发展的时代,对网络空间中准确流量的需求越来越明显。不论是网络安全行业、审计监管行业还是其他互联网企业,有效、高速且准确的网络流量重组技术都是后续各应用场景的数据来源基础,只有高度准确且高度可靠的数据源才能带给项目最坚实的基础。
本文通过查阅文献,对现有的分片重组技术做了详尽的分析,在理清了目前技术的局限性后,根据平衡树算法,提出了适用于大流量高并发的区间管理算法,并解决了TCP流分片重组流程,解决了因乱序、重发、查询效率低导致的重组效率低、重组完整度不足的技术难题。
猜你喜欢 分片报文数据包 基于J1939 协议多包报文的时序研究及应用汽车电器(2022年9期)2022-11-07上下分片與詞的時空佈局词学(2022年1期)2022-10-27二维隐蔽时间信道构建的研究*计算机与数字工程(2022年3期)2022-04-07民用飞机飞行模拟机数据包试飞任务优化结合方法研究民用飞机设计与研究(2020年4期)2021-01-21分片光滑边值问题的再生核方法数学物理学报(2020年5期)2020-11-26CDN存量MP4视频播放优化方法广东通信技术(2020年10期)2020-10-26CTCS-2级报文数据管理需求分析和实现铁道通信信号(2020年4期)2020-09-21浅析反驳类报文要点中国外汇(2019年11期)2019-08-27基于模糊二分查找的帧分片算法设计与实现火控雷达技术(2018年4期)2019-01-15SmartSniff网络安全和信息化(2018年4期)2018-11-09本文来源:http://www.zhangdahai.com/shiyongfanwen/qitafanwen/2023/0913/653502.html



