【www.zhangdahai.com--其他范文】
郑大勇,王艳辉(通信作者)
(通化师范学院 吉林 通化 134002)
1.1 HTML5
HTML5是超文本标记语言(hyper text markup language,HTML)的第5次重大修改,2014年10月由万维网联盟(World Wide Web Consortium,W3C)完成标准制定。HTML5的设计目的是在移动设备上支持多媒体,它是网页前端的标准书写语言,是构建Web的重要工具。现如今,HTML5是Web中的核心语言,是网站开发技术人员必须要掌握的一项技术。随着移动互联网的发展越来越多,行业巨头正不断向HTML5靠拢。除苹果、微软、黑莓之外,谷歌的Youtube已部分使用HTML5;
Chrome浏览器宣布全面支持HTML5;
Facebook则不遗余力地为HTML5进行着病毒式传播。
1.2 CSS3
CSS3是层叠样式表(cascading style sheets,CSS)技术的升级版本,于1999年开始制订,2001年5月23日W3C完成了CSS3的工作草案。在网页制作时采用层叠样式表技术,可以有效地对页面的布局、字体、颜色、背景和其他效果实现更加精确的控制。只要对相应的代码做一些简单的修改,就可以改变同一页面的不同部分,或者页数不同的网页外观和格式。CSS3语言开发是朝着模块化方向发展的,把它分解为一些小的模块,更多新的模块也被加入进来。CSS3主要包括盒子模型、列表模块、超链接方式、语言模块、背景和边框、文字特效、多栏布局等模块。
1.3 JavaScript
JavaScript是一种直译式脚本语言,也是一种动态类型、弱类型、基于原型的语言,内置支持类型。它的解释器被称为JavaScript引擎,为浏览器的一部分,广泛用于客户端的脚本语言中,最早是在HTML(标准通用标记语言下的一个应用)网页上使用,用来给HTML5网页增加动态功能。1995年,由Netscape公司的Brendan Eich,在网景导航者浏览器上首次设计实现而成。因为Netscape与Sun合作,Netscape管理层希望它外观看起来像Java,因此取名为JavaScript。
2.1 HTML5到JavaScript
HTML5和JavaScript之间的依赖主要有两大类:1)从HTML5到JavaScript文件的链接。链接的依赖源于HTML5文档所在的代码,HTML5文档中包含对JavaScript文件的引用实现动态效果。2)HTML5文件中的事件监听器。JavaScript作为序事件驱动的语言,对事件的监听是必不可少的。事件监听就是为了让计算机随时能够发现用户与网页的交互动作,计算机发现事件发生了,从而执行程序员预先编写的一些程序。
2.2 HTML5到CSS3
定义CSS3规则中最常用的CSS选择器是类选择器,类选择器允许以一种独立于文档元素的方式来指定样式。该选择器可以单独使用,也可以与其他元素结合使用。一个类选择器标识为模型中的一个依赖项。
2.3 JavaScript到HTML5
JavaScript到HTML5之间可以通过文档对象作为依赖项的,这样的引用用于获取HTML5元素的句柄执行事件绑定、DOM操作等。如果引用没有存在,它会导致JavaScript出现错误。
2.4 JavaScript到CSS3
JavaScript到CSS3之间的依赖项是JavaScript和HTML5之间依赖关系的扩展。研究中看到JavaScript可以使用文档访问HTML5元素对象,一旦使用JavaScript代码获得了对任何元素的引用,就可以将一个CSS3类赋给HTML5元素。
2.5 CSS3到HTML5
用于定义CSS3规则的2个常见CSS选择器,是类选择器和id选择器。类选择器在HTML5中会被标识为对CSS3的依赖项,另一个依赖项是由id选择器生成的。这种依赖性在CSS3规则中使用id选择器访问HTML5中的具体唯一元素。
2.6 CSS3到JavaScript
在本文范围内,没有确定CSS3和JavaScript任何相关的依赖关系。尽管存在一些依赖项,如从JavaScript使用文档访问HTML5元素对象,再将一个CSS3类赋给HTML5元素,但这已经在JavaScript对CSS3的依赖中覆盖了。
3.1 HTML5解析
对于HTML5的解析,使用了Jsoup解析器。Jsoup是一款Java的HTML解析器,这是一个流行的Java库。Jsoup解析器支持所有最新的HTML5标签,能够从URL、文件或字符串解析HTML5。Jsoup解析器将HTML5解析为文档对象模型(document object model,DOM),用于在HTML5文档中表示对象(节点),也为DOM访问和遍历提供了一个非常简单的应用程序接口(application programming interface,API)。API中基于正则表达式的选择器,使其非常灵活。Jsoup解析器可生成一个解析树,但是DOM是通过API作为“Document”对象公开的。虽然Jsoup解析器提供了这么多漂亮的功能,但一个主要的缺点是它没有跟踪行号。因此,一个基于Java的Matcher引擎自定义模块,用于跟踪行号和列号十分重要。
根据用以分析的源目录,将所有的HTML5文件根据文件扩展名提取,一旦所有的HTML5文件被识别,每个文件均可使用Jsoup解析器解析。对每个文件提取文件对象,最简便的方法,如:getAllElementIds、getAllElementClasses、getScriptLinks和getEventHandlers,均实现了递归遍历元素对象并提取所需的数据。从这些方法中,提取每个HTML5文件可以得到以下数据:1)使用所有“id”属性;
2)使用所有“类”属性;
3)链接到所有相关的CSS3样式表;
4)链接到所有相关的媒体资产(图像、视频、音频等);
5)所有相关JavaScript文件的链接;
6)所有通过事件处理程序引用的方法。
此外,解析器允许检查存储为Parse Error的语法错误,上述数据可用于每个文件、每个引用文件(CSS3文件、JavaScript文件或资产文件)被检查是否存在和路径有效性。如果没有找到任何文件,则产生FileNotFound依赖错误。之后,每个关联的CSS3文件和JavaScript文件被解析和分析其他依赖关系。
3.2 解析CSS3
基于此项目的目的,使用CSS3的现代Web应用程序。为了避免解析缺陷并提取准确的选择器列表,研究使用了一种用于CSS3的SAC解析器。SAC解析器是一个解析CSS3文件的Java库,支持CSS1、CSS2和CSS3。SAC解析器接受CSS3文件文本作为输入,并生成DOM,这个解析器的优点是它允许附加一个错误处理程序来跟踪解析每个规则生成的错误。与每个HTML5文件相关的所有CSS3文件,均可使用此解析器处理。一旦HTML5解析阶段完成,所有有效的关联CSS3文件被识别,每个文件被传递到CSS3解析器。对于每个CSS3文件,可以提取以下数据:1)引用id列表;
2)定义类的列表。一旦获得了这些数据,静态分析器就会使用这些信息分析基于类和id引用的依赖项。
3.3 解析JavaScript
本文选择了Nashorn引擎,以解析JavaScript。Nashorn引擎是由Oracle开发的JavaScript引擎,在之前与Java8及以上版本捆绑在一起,它的速度与Chrome的V8引擎相当。与每个HTML5文件相关的所有JavaScript文件,均使用这个解析器处理。一旦HTML5解析阶段完成了所有有效的相关JS文件,那么每个文件均会传递给JS解析器。对于每个JS文件,可以提取以下数据:1)引用id列表;
2)引用类的列表;
3)定义的所有方法的方法签名。对象的位置将存储每个文件的所有上述信息。
3.4 整合解析器结果
一旦收集了所有相关文件中的数据,就会将其与依赖项进行比较当他们出现的时候。如,在JavaScript文件中识别id列表时,这些id会同时与HTML5文件中的现有id进行比较。如果一旦发现错误,它就会立即存储在Results对象中,稍后再进行检索显示,CSS3文件处理的情况也类似。当找到依赖项,而不会导致运行时错误,作为警告存储在Results对象中。根据详细级别,用户可以选择查看详细信息。
3.5 基于规则的分析
基于规则的分析,有助于帮助用户过滤掉一次一个类别的结果和视图。错误作为错误分类的一部分进行讨论,其输出结果是根据标志值进行筛选的,并且内部计算也是一样的。这样的原因是需要避免任何依赖和错误的计算分析被忽视。该标志支持的值有:1)ParseError,将过滤掉结果,只显示遇到的解析错误,同时解析HTML5、CSS3或JavaScript。2)ReferenceError,将过滤掉结果以显示引用错误,引用错误可以是各种类型,如不存在的类、不存在的id和不存在的函数。3)FileNotFound,将过滤掉结果,显示未找到文件的错误。值得注意的是,此处也检查远程文。4)警告,将过滤结果,只显示警告,以此来警告那些不会导致运行时错误的依赖项。
4.1 一般静态分析工具的流程
独立的命令行工具和安装在集成开发环境(integrated development environment,IDE)上的插件是大多数静态分析工具有2种类型,但有着不同的用途。独立的命令行工具可以集成到构建工具链或持续集成工具,而集成插件可以服务于IDE中交互式实用程序,帮助开发人员在编写代码时处理缺陷。此工具也采用了类似的方法。当浏览器接收到一个请求网页时,它首先获取HTML5文件,一旦文件被检索,它就会启动解析HTML5文档,HTML5标签被转换成DOM节点在“内容树”。然后,从各种样式中解析样式数据源码,包括CSS3样式表和内联样式标签,以及内容树样式信息被合并生成“渲染树”。经过一个“布局”过程,最终在浏览器上绘制,这个绘制的图层便是用户在浏览器上所看到的内容。静态分析工具流程,如图1所示。基于内部解析优化技术,HTML5在获取相关脚本文件时,文档解析可能会停止,也可能不会停止和解析。一般流程解释了浏览器如何加载网页。

图1 静态分析工具流程
4.2 优化后静态分析工具的流程
静态分析工具的主要目的是识别HTML5、CSS3和JavaScript之间的依赖关系,为了达到此目的,本文使用不同的解析器来解析这些语言并跟踪依赖关系。网页渲染流与网页相关的JavaScript获取和解析流程,如图2所示。
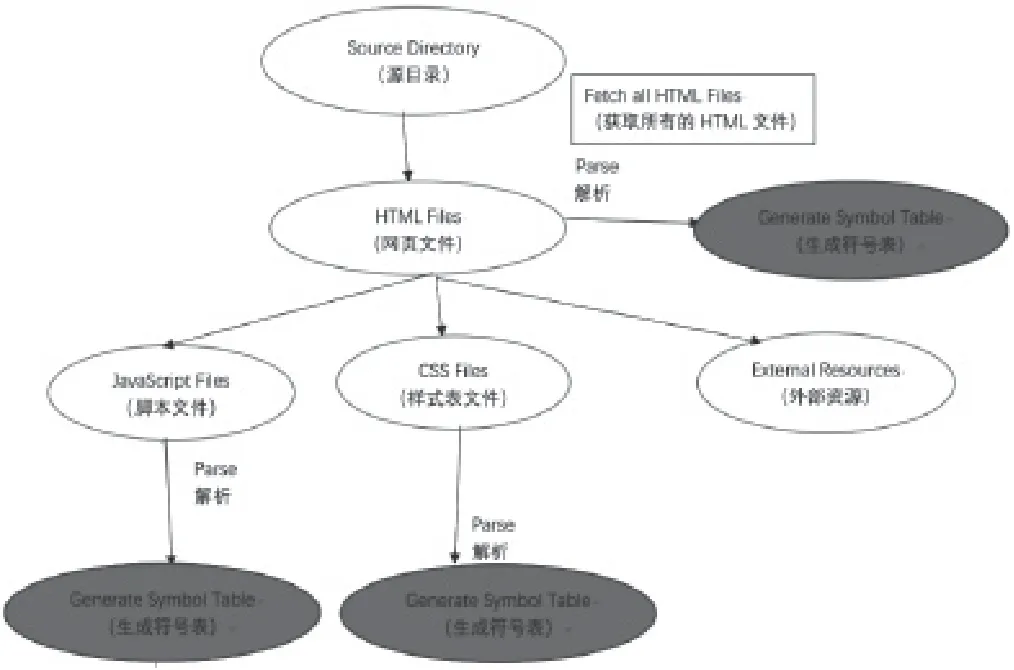
图2 网页渲染流与网页相关的JavaScript获取和解析流程
Web应用中的HTML5文件是通往整个代码库的大门,静态分析工具还通过构建一个HTML5列表,来分析指定目录中的文件并从那里移动。此外,跟踪与每个依赖项相关的元数据,以帮助开发人员查找并尽快修复缺陷。元数据包括源文件、行号、列号和依赖项类型。该工具的次要功能包括:提供详细的输出,输出结果在JavaScript对象表示法(JSON)和纯文本格式,显示JSON结果的HTML查看器,基于规则的分析,修复建议和集成插件开发。
对于开发人员来说,跟踪代码库的语法及跨HTML5、JavaScript和CSS3堆栈的依赖项均是开发过程中的挑战。开发人员手动检查工具和运行情况时,大量的由于语法依赖而产生的缺陷容易被忽视,从而出现人为错误。此外,往返代码编辑器和浏览器之间,增加了开发时间和成本,这些因素将会对整个开发团队的聚合导致严重的后果并影响最终产品。通过创建模型和工具的解决方法,识别和快速解析HTML5、CSS3和JavaScript的依赖项,以提高Web开发人员的开发效率和生产力。从设计的角度来看,工具也可以进一步改进,使之成为实时的,而不是即时工具的当前实现。
猜你喜欢选择器浏览器网页74151在数据选择和组合逻辑电路中的灵活应用科学与财富(2019年19期)2019-12-11反浏览器指纹追踪电子制作(2019年10期)2019-06-17基于CSS的网页导航栏的设计电子制作(2018年10期)2018-08-04基于HTML5静态网页设计魅力中国(2018年5期)2018-07-30DIV+CSS网页布局初探数码世界(2018年5期)2018-06-04四选一数据选择器74LS153级联方法分析与研究电脑与电信(2017年6期)2017-08-08基于URL和网页类型的网页信息采集研究电子制作(2017年2期)2017-05-17环球浏览器环境与生活(2016年6期)2016-02-27网页制作在英语教学中的应用电子测试(2015年18期)2016-01-14双四选一数据选择器74HC153的级联分析及研究大学物理实验(2015年2期)2015-10-22本文来源:http://www.zhangdahai.com/shiyongfanwen/qitafanwen/2023/0917/655619.html



