【www.zhangdahai.com--其他范文】
王宏乐,王兴林,李文波,邹阿配,叶全洲,刘大存
(1.华南理工大学环境与能源学院,广东 广州 510006;
2.深圳市丰农控股有限公司,广东 深圳 518055;
3.深圳市宇众物联科技有限公司,广东 深圳 518126;
4.深圳市丰农数智农业科技有限公司,广东 深圳 518055)
【研究意义】种子检测是作物质量检测的关键环节,也是品种选育、新品种审定和推广的重要依据。种子的传统检测方法主要依赖于人工或电子计数仪,存在效率低、误差大、耗时耗力等问题[1-3]。Duan 等[4]研发了一种采用单色线阵列相机进行稻粒图像在线采集的水稻谷粒考种系统,该系统能够分析稻粒总粒数、实粒数、空粒数和千粒重,但仍存在设备体积太大、功能不够完善、使用不便利等问题。随着深度学习技术的快速发展,卷积神经网络(Convolutional neural networks,CNN)被运用于农业领域中的花、果以及种子计数等场景中[3,5-6]。Tan 等[7]报道了基于分割的水稻谷粒统计的算法;
Yu 等[8]报道了使用深度学习框架R-CNN进行水平框目标检测的方法对水稻小穗进行识别和计数,并获得了优异的效果;
Deng 等[9]通过改进R-CNN 网络结构优化了稻穗上谷粒检测的准确性,使漏检问题有所改善。新技术在考种领域的应用可以提高工作效率和准确度。在谷粒质量检测及水稻育种中,谷粒粒型(粒长、粒宽、长宽比)是品种选育、识别和衡量稻米外观品质的主要指标,与稻米食味品质以及商业价值显著相关,可以使用图像分割的方法、边界提取算法来实现该参数的快速计算[1,10-14],但尚未见使用目标检测的方法来计算谷粒长宽比的报道。探索建立谷粒计数检测和谷粒粒型参数提取相结合的可能性,可以简化考种的工作流程,同时提升检测效果以及探索其在考种中的应用。
【前人研究进展】目标检测是计算机视觉领域的基本任务之一。基于深度学习的目标检测算法有两大主流方向,分别是两阶段(Twostage)模型和一阶段(One-stage)模型[15]。两阶段模型以基于区域卷积神经网络(Regions with convolutional neural network,RCNN)的网络结构作为代表,第一步是计算生成候选框,第二步是通过深度学习对候选框进行特征提取,预测候选框的目标类别与目标位置[16]。两阶段模型由于要对候选框进行大量搜索,以及对大量候选框进行卷积操作,使得计算比较耗时[17]。一阶段模型以CenterNet 和YOLO(You only look once)系列为代表,可直接从输入图片中提取特征,同时确定目标物体的类别与定位,实现了更快的检测速度[18-19]。传统的目标检测器通过水平边界框(Horizontal bounding boxes,HBB)定位对象。HBB 具有良好的鲁棒性,但准确性不足,在许多实际应用中具有一定的局限性,如文本识别、遥感目标检测等,这些目标物体都具有任意方向性、高纵横比和密集分布的特征,因此,基于HBB 的模型可能会导致严重的重叠和噪声[17]。
为了解决这类问题,Ma 等[20]提出了基于旋转的边界框(Bounding box),并将之引入RPN架构,实现了遥感图像任意方向的文本检测;
Zhou 等[21]提出一种新的旋转目标定义方式,通过学习特征点到旋转框的四边距离以及角度信息,实现了一阶段文本检测;
Yang 等[22]提出一种新的一阶段旋转目标检测网络(R3Det),该框架通过特征插值将当前精炼的边界框位置信息重新编码为对应的特征点,以实现特征重构和对齐,从而获取更准确的特征以提高旋转目标检测性能。该方法的优点是可以更好地分离密集分布的目标物体,避免相邻边界框的重叠,以及减少捕获目标而引入的背景噪声。目前,流行的基于回归方式的角度预测方法存在一些边界问题,会导致产生一个较大的损失值,因此,Yang 等[23]提出环形平滑标签(Circular smooth label,CSL)方法,将角度的回归问题转换成一个分类问题,通过限制预测结果的范围来消除这一问题。随后,Yang 等[24]进一步从过于厚重的预测层以及对类正方形目标检测不友好等方面优化了CSL 旋转目标检测网络,提升了检测精度。尽管上述方法在旋转目标检测方面取得很大进步,但是旋转边界框的引入还是会存在一些小问题,比如较小的角度变化将导致交并比(Intersection over union,IoU)迅速下降,导致检测结果不准确。为了解决这一问题,一种比较好的方法就是解耦旋转锚框的匹配,将旋转边界框(Oriented bounding boxes,OBB)视为水平边界框(HBB)和角度的组合,匹配过程基于旋转解耦边界框的IoU 而非OBB,因此锚框匹配的稳定性会更好[17]。
【本研究切入点】传统水平框检测虽已得到广泛应用,并具有相当准确率,但对不规则的目标物体特征提取仍十分有限。解耦的旋转锚框匹配策略是基于特征金字塔网络(FPN)的结构,该结构采用了多尺度特征融合技术,对小目标物体检测效果有比较明显的提升,适合于遥感和水稻谷粒等小目标物体检测。【拟解决的关键问题】相比传统HBB 检测中存在大量非目标背景区域,不能准确计算出水稻谷粒的长宽比,不利于检测目标区域准确的面积计算,使得传统水平框目标检测不能在考种中对谷粒长宽比进行有效计算。传统水平框的目标检测方法,因标注区域存在非目标区域,以及水平框标注不能解决密集分布目标的重叠问题,较难实现对密集分布目标检测的准确区分,经常存在漏检情况。本研究旨在设计一种解耦的旋转锚框匹配策略,在保证检测精度的同时实现稻谷长宽比的快速准确计算,简化考种工作流程,开发方便快速的基于计算机视觉目标检测的谷粒检测新方式,并探索基于这种锚框匹配策略在考种中的应用。
1.1 数据采集、特征标注及处理
水稻谷粒数据集的采集设备为CANON powershot A70,像素为320 万,拍摄时光源为自然光,光照强度为100~1 000 lx。将水稻谷粒置于黑色或白色背景板上,谷粒随机排列。相机固定于50 cm 高处用于水稻谷粒图像采集,采集的图像中的谷粒数量为1~500 不等。
为降低重复图片数量以及无谷粒图片对模型训练的干扰,使用人工筛选的方法对采集图像进行数据清洗,即删除同一个样本的重复图片。清洗后的数据采用人工划分方法,使用Rolabelimg软件[23]对目标谷粒分别进行水平框和旋转框的框选,对图像边缘显示的谷粒面积≥30%以上进行标定,否则不标定。水平框标注采用(x,y,w,h)表示,其中(x,y)是目标框的中心坐标,w和h是分别沿X 和Y 轴的边界框的长度。旋转框标注采用(x,y,h,w,θ)表示(图1),θ为旋转框与水平线的夹角。

图1 训练集图片的不同标注方式Fig.1 Different types of annotations of bounding boxes in training datasets
自建的水稻谷粒数据集包含144 张标注的图片,其中训练集96 张,测试集和验证集各24 张,白色背景和黑色背景数据各50%,共包含2 922个谷粒样本,图片分辨率为20 161 512。验证集用于平均准确率(Mean average precision,mAP)的计算,测试集用于计算召回率和精确率。将图片尺寸调整到640×640,用于训练与测试。
1.2 检测方法
1.2.1 网络结构 水平标注水稻谷粒图像使用YOLOv5l 的网络体系结构,模型的深度和宽度均为1,参照李志军等[24]的方法进行实验,将前景和背景IoU 阈值设置为0.3。本研究参照解耦旋转框检测匹配策略(Rotation-decoupled detector,RDD)的方法[17],首先从骨干网络中获取多尺度特征图,其次是将多尺度特征图输入金字塔结构网络进行特征融合。金字塔网络实现了语义信息的传输,这有助于进行多尺度目标检测。为了连接不同比例的特征层,对特征图进行上采样,并将其与上一层特征图的对应元素相加。在求和前后,添加卷积层以确保检测特征的可分辨性。最后,预测层输出分类和回归。分类和回归使用具有相同结构的两个预测层,并且它们仅在输出通道数上有所不同。分类的输出通道数为a×c,回归的输出通道数为a×5,a、c 分别对应锚点和类别的数量,所示结构在实践中也可以扩展到更多的层。在训练阶段设计旋转解耦的锚框匹配策略,随后的模型只使用水平锚框,而不是旋转锚框。本研究选择ResNet101 和DarkNet53[16-17,25]进行试验。
1.2.2 边界框表示 本研究采用一种新的边界框表示方法,结合了HBB 和OBB 方法各自的优点,这种边界框表示方法将OBB 分类成两类,一类为长边沿水平方向的矩形框(x,y,w,h),另一类为长边垂直水平方向的矩形框(x,y,h,w),任何OBB 都可以由这两类HBB 来表示,它们具有相同的形状和中心点,它们之间的夹角θ被约束在[-π/4,π/4]之内,这个夹角θ重新定义为新边界框的角度。新的旋转边界框的表示与传统HBB 表示方法较类似,在与真实框(Ground truth)进行匹配计算时,能有效避免OBB 带来的角度周期性问题。此外,传统的旋转检测器为了获取任意角度目标物体的准确检测,采取了大量旋转锚框设置,相比之下,新的旋转边界框表示减少了大量锚框的使用,极大地优化了模型训练与推理过程。
1.2.3 旋转解耦锚框匹配策略 基于上述定义的边界框,可以实现一种旋转解耦的锚框匹配策略。首先将旋转的边界框或者真实框解耦为长边平行或垂直水平方向的矩形框和一个夹角,其中解耦后的矩形框被用作新的真实框进行匹配,这样旋转框的夹角就不会参与到真实框的匹配过程,减少角度周期性引入的干扰。具体来说,当IoU 大于前景给定阈值时,将锚框分配给真实框并归入前景(正样本)参与训练;
当IoU 低于背景给定阈值时,将锚框归为背景(负样本)参与训练。本研究将前景IoU 阈值设置为0.5,将背景IoU 阈值设置为0.4。为了使得锚框能够更好地与不同尺度不同方向的真实框进行匹配,这里使用了7 个宽高比{1、3/2、2/3、3、1/3、5、1/5、8、1/8}的水平锚框,每个水平锚框再使用3 种不同尺度{20、21/3、22/3}的缩放。
1.2.4 损失函数 对于目标检测问题,损失函数都会包括分类问题和回归问题的损失函数。对于分类损失,根据前面设置的正负样本IoU 阈值,图片在锚框与真实框匹配过程中会被标记为正样本或者负样本,由于大量图片的真实目标占比较少,所以标定的负样本会远远多于正样本,从而导致训练过程中正-负样本不平衡问题。为了缓解这种不平衡问题,分类损失采用当前使用比较流行的Focal loss 损失函数(Lcls),计算方法参照Lin 等[26]的方法。对于回归损失,如果直接使用绝对坐标预测真实框,会导致定位不准确。由于真实框尺度不一致,预测框与真实框的相同偏差对不同尺度真实框的误差表现会不一样,尺度大的真实框误差表现较小,尺度小的真实框误差表现较大,因而直接预测绝对坐标所产生的loss 不能真正反映预测框的好坏,因此采用目前流行的偏移量进行回归预测,回归损失(Lreg)的计算参照Zhong 等[17]的方法。总的损失函数(Ltotal)由分类损失和回归损失组成,表示为Ltotal=Lcls+λLreg,两项之间的权衡由平衡参数λ 控制,本研究将λ 设置为1。
1.3 模型训练
本研究在台式计算机上,基于PyTorch 深度学习框架实现改进模型和训练算法。台式计算机配有NVIDIA V100 的图形处理器(GPU),搭载Intel(R) Xeon(R) Gold 5218 CPU@2.30GHz,内存为128 GB。实验环境为Ubuntu 18.04 LTS 64 位系统、Cuda11.3、Cudnn8.1.0、Pytorch1.7.1、Python3.7。
本研究模型训练使用YOLOv5l 进行水平框标注图片的训练,使用DarkNet53 和ResNet101 进行旋转框标注图片的训练。水平框和旋转框标注图像训练采用的批处理大小为64,输入图像统一分辨率为640×640。其中旋转框标注图片训练使用衰减系数为5×10-4、动量为0.9 的随机梯度下降(Stochastic gradient desent,SGD)作为优化器,初始学习率设置为0.001,学习率调整策略为带热重启的随机梯度下降(Stochastic gradient descent with warm restart,SGDR)[27-28],基本周期为1,倍率为2,每个周期开始时学习率为基础学习率,结束后学习率降为0,学习率退火方式为余弦退火[29]。实验共设计3 种不同的迭代次数,分别为3 600、5 040、6 000 次。
1.4 水稻谷粒长宽比计算
从测试集中随机抽取32 粒稻谷计算长宽比。水稻谷粒的真实长宽比由游标卡尺测量及计算,长宽比为谷粒的真实长度(h)与宽度(w)的比值。使用HBB 和OBB 检测模型预测的谷粒长宽比(Aspect ratio,AR)计算公式如下:

平均长宽比为32 个水稻谷粒测量值或预测值的平均值。预测结果的准确性使用均方根误差(Root mean square error,RMSE)进行评价。数据分析使用SAS 软件(Release 8.01)和EXCEL2007软件;
利用方差分析(ANOVA)及邓肯氏新复极差法(Duncan’s Multiple Range Test,DMRT),在P=0.05 水平上进行差异显著性分析。
用相同的验证集和测试集样本对构建的基于HBB 的YOLOv5l 模 型、基 于OBB 的ResNet101和DarkNet53 模型进行测试,结果如表1 所示。由表1 可知,所有模型平均精度均值(Mean average precision,mAP)在88.69%~94.80%之间,精确率为99.47%~100.00%,召回率为95.95%~99.47%。其 中,YOLOv5l 模型的mAP 值略高于基于OBB 的ResNet101 和DarkNet53 模 型;
除迭代3 600 次的ResNet101 模型的召回率为95.95%,低 于YOLOv5l 模型的97.71%~98.06%外,其余基于OBB 训练的模型的召回率均不低于YOLOv5l 模型。这表明基于OBB 的ResNet101 和DarkNet53 模型以及基于HBB 的YOLOv5l 模型均对谷粒图像具有较高的识别精度,基于OBB 的目标检测的深度学习方法可成功对谷粒图像进行准确识别。图2 为YOLOv5l(水平框)、ResNet101(旋转框)以及DarkNet53(旋转框)3 种网络结构分别迭代6 000 次的模型在测试集上的检测结果,蓝色框表示漏检,黄色框表示误检,边缘少于30%的谷粒不纳入统计。
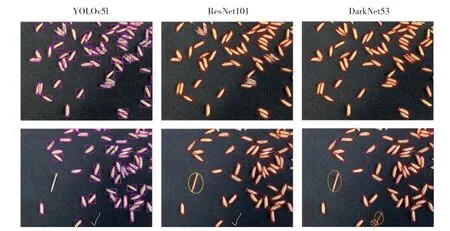
图2 3 种不同网络结构的模型在测试集上的谷粒检测结果Fig.2 Grains detection results of three different network structures in test datasets
2.1 模型迭代次数对谷粒识别率的影响
本研究选择YOLOv5l 网络结构对水平框标注图片进行训练,选择ResNet101 和DarkNet53 对旋转框标注图片进行训练。模型训练迭代次数分别为3 600、5 040、6 000 次。由表1 可知,不同网络结构模型的mAP 均随迭代次数增加而增加,当迭代次数从3 600 次增加到6 000 次时,mAP增加幅度最小的网络结构模型为ResNet101,变化值为0.33%;
其次为YOLOv5l,mAP 增加幅度为0.80%;
mAP 增加幅度最大的是DarkNet53,变化值为3.54%。同时,所有模型的召回率也随迭代次数增加而增加,当迭代次数从3 600 次增加到6 000 次时,ResNet101 的召回率从95.95%增加到98.59%,变化值为2.64%;
YOLOv5l 的召回率从97.71%增加到98.06%,变化值为0.35%;
DarkNet53 的召回率从98.94%增加到99.47%,变化值为0.53%。

表1 不同方法在水稻谷粒测试集的检测精度对比Table 1 Comparison of detection accuracy of different methods in rice grains test dataset
2.2 不同方式标注对模型谷粒识别率的影响
由表1 可知,使用水平框标注图片训练的YOLOv5l 模型的mAP 值均在94%以上,略高于使用旋转框标注图片训练的DarkNet53 和ResNet101 模型。但这3 种不同网络结构训练得到的模型的召回率差别不大,以DarkNet53 明显优于YOLOv5l 和ResNet101,而在迭代次数大于5 040 次后,ResNet101 表现优于YOLOv5l。由图2 可知,使用旋转框标注图片训练的模型检测到的目标物体中包含的非目标背景区域占比更少;
当目标样本密集分布时,使用水平框标注图片训练的YOLOv5l 模型存在漏检情况,而使用旋转框标注图片训练的ResNet101 和DarkNet53 模型的漏检情况得到明显改善。相比使用水平框标注图片训练的YOLOv5l 模型,ResNet101 和DarkNet53在误检上表现稍为逊色;
当YOLOv5l 模型迭代次数大于5 040 次时的精确率可达100.00%,而在使用旋转框标注图片训练得到的模型中,除ResNet101-3600 精确率为100.00%外,其他模型的精确率均在99.00%以上。
2.3 不同方式的标注对模型在谷粒长宽比计算的影响
由表2 可知,使用基于YOLOv5l 的HBB 检测模型计算得到的谷粒平均长宽比范围为2.14~2.16,使用OBB 检测模型计算得到的谷粒平均长宽比范围为3.37~3.57,真实值的谷粒平均长宽比为3.57。与真实值相比,HBB 检测模型计算结果的均方根误差为9.38~9.45,而旋转框检测模型的计算结果的均方根误差值为0.91~2.29,且训练迭代次数增加与预测准确性无明显相关。显著性分析结果表明,基于YOLOv5l 的HBB 检测模型的计算结果与真实值存在显著差异,而基于DarkNet53 和ResNet101 的OBB 检测模型的计算结果与真实值无显著差异。结果表明,HBB 检测模型不能准确地计算水稻谷粒的长宽比,而使用OBB 检测模型可以准确预测并计算水稻谷粒的长宽比。

表2 不同模型计算的水稻谷粒长宽比Table 2 Aspect ratios of rice grains calculated by different models
传统的水平框检测虽然具有不错的准确率,但对细长的密集物体依然存在漏检现象,且不利于准确提取该类物体的长宽比。因此,开发谷粒计数与谷粒长宽比提取相结合的轻量型模型很有必要,在谷粒质量快速检测以及品种快速鉴定的场景中具有实用意义。本研究中,HBB 检测模型YOLOv5l 的mAP 值略高于OBB 检测模型DarkNet53 和ResNet101。OBB 相 比HBB,增 加了边界框的角度θ,而θ具有周期性,会导致IoU突然下降,同时预测框角度的较小变化,对IoU造成很大损失[17,22],这可能是造成其mAP 低于HBB 的主要原因。本研究使用的OBB 检测方法,误检率高于水平框的传统检测方法,仍需进一步优化以降低误检率。
水稻谷粒的长宽比与其品种、质量等级、价格息息相关,其中杂质和不完善粒的比例极大影响谷粒的质量等级和价格,也是粮食育种选择、品种鉴定的重要参数之一[10-13,29]。Gotmare 等[28]使用MATLAB 处理图像提取谷粒的空间参数信息来计算谷粒的长宽比及粒径分布,误差率约为10%左右,但在当时的环境条件下运行缓慢,没有实用性。随着计算机技术的快速发展,基于深度学习的图像分割技术也可用于种子计数及长宽比计算,但训练需要的图像标注方法复杂,耗时费力,计算相对耗时,而且分割计算种子长宽比采用的是分割结果的外接矩形框,因此受分割准确度影响较大[3,5-6,8,31-32];
相比之下,本研究建立的谷粒计数及长宽比计算方法具有标注简单、计算速度更快的优点,而且能直接输出种子长宽比,具有较强的实用性。
水稻谷粒性状包括形状、形态、纹理等指标,其中粒长、粒宽、长宽比、圆度与水稻产量和外观品质直接相关[10-13,33-35]。本研究使用的旋转框目标检测方法可实现较高精度的谷粒计数及谷粒长宽比的快速计算,但目前无法实现其他指标如截面积、圆度等的精细测量。黄成龙等[11]报道了基于X-ray 透射成像的稻穗米粒的检测测量方法,包括谷粒粒型、长度、宽度及饱满度,平均误差小于2%,但X-ray 的采集设备十分昂贵。本研究使用的旋转框检测策略在迭代6 000 次后具有不错的测量精度,测量的长宽比与实际测量值相比均方根误差均小于1,且本研究建立的谷粒计数及长宽比计算方法仅需普通摄像头拍摄可见光照片即可实现,具有方便、价格低廉的优点。
本研究使用的方法对密集谷粒的漏检存在一定改善,但仍存在对非谷粒物体的误检情况,有待进一步优化。在进一步的研究中,将考虑通过准备掺混不同谷粒杂质,并通过计算目标物体的长宽比来实现杂质检测的方法来尝试实现净度分析、种子真实性和品种纯度鉴定,同时与现行标准方法[33]的结果进行比较来进一步验证方法的可行性及可靠性。
本研究结果表明,与HBB 检测方法相比,使用OBB 检测方法,更加适合高纵横比及密集分布的目标检测,如谷粒检测。该方法相比传统水平框的检测方法,具有以下优点:(1)检测目标中包含的背景噪声占比更少,因而具有更高的准确率。相比传统HBB 检测中存在大量非目标背景区域,不能准确计算出水稻谷粒的长宽比,不利于检测目标区域准确的面积计算,使得传统水平框目标检测不能在考种中对谷粒长宽比进行有效计算,而OBB 检测的方法大大改进了这两项缺点,可准确计算水稻的长宽比,可考虑进一步开发并应用于谷粒质量检测或品种识别场景。(2)该方法可解决传统HBB 检测中对距离较近的谷粒的漏检问题。传统水平框的目标检测方法,因标注区域存在非目标区域以及水平框标注不能解决密集分布目标的重叠问题,较难实现对密集分布目标检测的准确区分,经常存在漏检情况。而使用旋转框的目标检测方法可以有效解决漏检问题,从而提升目标检测的召回率。综上所述,本研究证明了旋转框的目标检测方法在谷粒检测场景中进行计数和长宽比计算应用的可行性,可实现高效准确地进行谷粒长宽比的计算,通过进一步优化和开发可运用于种子质量检测及品种鉴定等数字化育种场景中。
猜你喜欢 锚框谷粒边界 锚框策略匹配的SSD飞机遥感图像目标检测计算机与生活(2022年11期)2022-11-15基于SSD算法的轻量化仪器表盘检测算法*计算机工程与科学(2022年8期)2022-08-20基于GA-RoI Transformer的遥感图像任意方向目标检测中南民族大学学报(自然科学版)(2022年3期)2022-05-08拓展阅读的边界儿童时代·幸福宝宝(2021年11期)2021-12-21探索太阳系的边界小学科学(学生版)(2021年4期)2021-07-23食言者作文小学中年级(2020年9期)2020-12-29食言者作文·小学低年级(2020年9期)2020-11-30意大利边界穿越之家现代装饰(2020年4期)2020-05-20基于深度学习的齿轮视觉微小缺陷检测①计算机系统应用(2020年3期)2020-03-18食言者作文小学中年级(2019年5期)2019-01-10本文来源:http://www.zhangdahai.com/shiyongfanwen/qitafanwen/2023/0822/643613.html



