【www.zhangdahai.com--其他范文】
汪 磊 何怡刚 谭 畅
(1.武汉大学 电气与自动化学院,武汉 430072;2.国家电网湖北超高压公司,武汉 430000)
近年来,为了解决环境污染和能源危机的问题,推进能源转型势在必行[1].根据国家能源局2020年公布的新能源装机数据显示,2020年新增风电装机7 167万k W、太阳能发电4 820万k W,风光新增装机之和约为1.2 亿k W.随着风电装机容量的不断增长,越来越多的风电场被安设在高海拔、严寒的地区.在恶劣的气象条件下,风电机组的叶片出现结冰风险的概率较大.叶片结冰会影响风机的空气动力效率和扭矩,导致涡轮机停机、功率损失和涡轮机部件损坏[2].因此,风机叶片覆冰的有效检测成为避免上述问题的关键,这对于确保风电系统的可靠性、稳定性和经济性运行具有现实意义.
目前,针对风机叶片覆冰检测的传统研究方法包括直接法和间接法[3].直接法是指直接测量由叶片表面上的冰沉积引起的特性变化,例如:质量、信号反射、介电常数、电感和电导率等.直接法涉及的检测手段包括:频率检测、光纤检测、红外检测和超声检测等[4].通常,直接方法需要额外放置传感器,这会增加相关成本.此外,传感器本身也容易出现设备老化、检测值漂移等问题,给实时覆冰检测带来了困难.间接方法首先收集数据,例如:环境温度和湿度、风力涡轮机功率损失;然后根据这些特征与叶片结冰程度之间的相关性建立叶片覆冰检测模型.一般来说,间接方法存在一些缺点,例如:缺乏普遍性、鲁棒性低以及对结冰机制的依赖性强.
随着数据采集与监视控制(SCADA)系统在风电行业的广泛应用,研究人员可以获得风电机组每个组件或子系统的大量状态检测数据.数据驱动方法不用掌握复杂的物理机制,这是因为这类方法可以通过挖掘历史数据中的隐藏信息来检测叶片的结冰状态.数据驱动方法包括浅层机器学习和深层机器学习方法.从本质上来说,叶片覆冰检测是一个经典的时间序列分类问题.浅层机器学习,例如反向传播神经网络(BPNN)、随机森林(RF)和支持向量机(SVM)等,都存在难以学习时间序列数据的时间相关性的缺陷,一般需要通过复杂的特征提取和特征增强来人为地添加时间特征以确保预测精度[5].具有循环结构的深度学习方法,比如:循环神经网络(RNN)、长短期记忆(LSTM)和门控递归单元(GRU)等,也被用于时间序列分析,这类方法具有较强的非线性拟合能力且能较好地学习时间序列的时间相关性特征.但是,这类循环网络模型不支持并行计算,训练效率不高[6].
自然语言处理(NLP)与时间序列分析非常类似.为了进一步优化NLP中循环结构模型的性能,谷歌提出了一种用于机器翻译的Transformer模型[7].该模型不存在循环结构,而是完全依靠自注意力机制来建立输入和输出之间的全局依存关系,可以学习序列的各种尺度的复杂依赖信息.同时,Transformer模型支持图像处理单元(GPU)并行运算,大大提高了模型训练效率[8].
考虑到上述分析中Transformer模型的诸多优点,本文对谷歌的Transformer模型进行了改进,使其可以用于时间序列分类.同时,蜻蜓算法(dragonfly algorithm,DA)[9]用于优化Transformer网络中的超参数.本研究设计了DA-Transformer的混合模型,实现了风机叶片的高精度覆冰检测.其主要贡献如下:
(1)使用DA-Transformer模型整合了风机的SCADA 系统的多传感器信息.它仅使用数据驱动的方法来捕获风机叶片覆冰的复杂特征,而无需构建复杂的物理模型和安装额外的传感器.
(2)提出的模型中的DA 可以避免人工调整超参数的困难.同时,与粒子群算法和遗传算法相比,DA在优化Transformer的超参数时,表现出更快的收敛速度和更优的收敛结果.
(3)为解决传感器数据的类不平衡和变量选择问题,本文采用重叠/非重叠滑动窗口分割法生成类平衡的样本;此外,采用基于决策树分类器的递归特征消除方法进行变量选择,不仅控制了数据规模而且提升了计算效率.
1.1 模型基础
自注意力机制是Transformer模型的核心基础,它是由注意力机制衍生出来的.注意力机制是可以描述为Query 到一系列Key-Value 对的映射,其中Source中的构成元素可以视为一系列Key-Value对数据.计算注意力值的过程主要分为3个阶段[7]:其一是使用点积、拼接或者感知器等函数计算Query和Key直接的相似度;其二是使用softmax函数来归一化第一阶段中获得的权重;其三是将权重和相应的值相加以获得最终注意力值.以上3个阶段的数学描述如下:

式中:L x为Source的长度;S为计算相似度的函数;A为注意力值.
缩放点积注意力模型[7]如图1(a)所示.其中Mat Mul和Scale分别是矩阵乘积和缩放操作,它是多头注意力模型的核心,由d k维的Query和Key以及d v维的Value组成,其输出是

图1 Transformer中的注意力模型

该模型可以作为注意力层,将n×d k的序列Q编码为n×d v的序列,分析Q中的每个子向量,并根据式(2)获得式(3)如下:

式中:z为归一化因子;q t、k s和v s分别为Q,K和V中的子向量.先计算每个k s和q t的内积,然后通过softmax函数获得q t和每个v s之间的相似性,最终通过加权求和得到d v维向量.
如图1(b)所示的多头注意力[7]是谷歌提出的一种新模型.其中Linear和Concat分别是线性化和拼接操作,它是对注意力机制的改进.该模型首先通过投影矩阵映射Q、K和V,然后执行注意力运算,此过程重复h次,最后将结果拼接起来,上述操作可以描述为:


自注意力[7]是指在时间序列内进行注意力计算,以寻找时间序列内部的联系.谷歌使用的是多头自注意力,可以描述为:

1.2 Transformer模型
为了解决多传感器数据的分类问题,本文在谷歌编码器-解码器结构的Transformer模型基础上进行了修改来处理时间序列,所提出的模型仅含有一个编码器,如图2所示.

图2 Transformer分类模型的结构
在编码器中,有一个输入层,一个位置编码层和n个相同的堆叠编码器层.每个编码器层中都包含一个多头注意力层和一个前馈层,编码器层中的每个子层之后是归一化层.SCADA 系统中采集的多维传感器数据通过输入层映射到dmodel维输入向量中,这有助于采用多头注意力机制.位置编码层通过正弦和余弦函数对传感器数据中的顺序信息进行编码来获得位置编码向量,然后将dmodel维的输入向量与位置编码向量的元素相加来获得带有位置信息的时间序列向量,该向量被送入n个编码器层中.最后一个编码器层的特征数据经过全连接层和Softmax层可以输出多传感器数据的分类结果.
1.3 蜻蜓算法(DA)
根据蜻蜓飞行、觅食和避敌的过程,Mirjalili在2016年首次提出了蜻蜓算法[9].蜻蜓在运动过程中的位置更新主要分为以下5种行为.
(1)分离行为是指蜻蜓个体与其相邻个体之间避免碰撞的过程,其数学模型为

式中:S i为第i个蜻蜓个体的分离;X为个体当前所在位置;X j为与个体相邻的第j个蜻蜓的位置;N为与蜻蜓i相邻的个体总数.
(2)对齐行为是指蜻蜓个体与相邻个体之间速度保持一致的过程,其数学模型为

式中:A i为第i个蜻蜓个体在参与对齐行为时的位置向量;v j为相邻个体的速度.
(3)凝聚行为是指蜻蜓个体向周围群体中心靠近的过程,其数学模型为

式中:C i为第i个蜻蜓个体在进行凝聚行为时的位置向量.
(4)觅食行为是指蜻蜓个体靠近食物源的过程,其数学模型为

式中:F i为第i个蜻蜓个体进行觅食行为时的位置向量;X+为食物源所处的位置.
(5)避敌行为是指蜻蜓防止自身被猎食时做出的反应,其数学模型为

式中:E i为第i个蜻蜓个体避敌行为的位置向量;X-为个体猎食所处的位置.
在模拟蜻蜓的群体行为的过程中,需要对其运动的步长ΔX和位置X矢量进行更新,其中步长向量显示蜻蜓的运动方向,可以描述为

式中:s为分离权重;a为对齐权重;c为凝聚权重;f为觅食权重;e为避敌权重;ω为惯性权重;t为当前迭代次数.
位置向量的更新分成两种情况,有邻近蜻蜓时可以描述为

无邻近蜻蜓时,位置进行更新采用随机游走公式:

式中:d为个体位置向量的维度;r1和r2取[0,1]之间的随 机数;β为 常量,取1.5;Γ(x)=(x-1)!.
1.4 基于DA-Transformer网络的风机叶片覆冰检测
本文提出了如图3 所示的DA-Transformer风机叶片覆冰检测模型.

图3 基于DA-Transformer的风机叶片覆冰检测
为了减少手动调整Transformer模型超参数的工作量,DA 用于自动优化这些超参数,从而获得最佳的Transformer检测模型.待优化的参数被看成是蜻蜓搜寻食物源的最优个体所处的空间位置,蜻蜓飞行在多维空间中搜索最优超参数组合,使得模型的适应度值最小.此外,为了说明本文方法在风机叶片覆冰检测的应用中具有更加普遍的适应性,在描述具体实现步骤时也考虑了特殊的数据驱动情景.具体实现步骤如下:
Step1:收集来自SCADA 系统的多传感器数据,并进行数据异常检测和清洗以提高数据质量;
Step2:对样本数据进行最大-最小归一化处理,并将它们映射到[0,1]之间.归一化公式为:

式中:xmin和xmax分别是样本数据集的最小值和最大值;x是原始样本数据.
Step3:利用变量选择来控制输入模型的数据规模、减少无关变量引发的噪声并提高模型的计算效率;
Step4:利用类平衡处理方法来避免类的严重不均衡对检测结果的干扰;
Step5:将整个数据集按照3∶1∶1的比例划分为训练集、验证集和测试集;
Step6:利用人工经验和DA 算法来获得不同超参数组合的候选Transformer模型;在训练集上训练这些候选模型并在验证集上评估它们.DA 算法优化超参数的过程包括:①设置待优化超参数的维度n d和取值范围,确定最大迭代次数Tmax和种群大小npop;②初始化蜻蜓种群,随机生成种群的位置向量X和步长向量ΔX;③据初始化超参数的值建立Transformer网络模型,对训练集和验证集的数据分别进行训练和评估,并将评估结果的二分类交叉熵损失函数作为每个蜻蜓个体的适应度值;④更新蜻蜓5种行为的权重s、a、c、f、e和惯性权重ω;⑤根据式(7)~(11)更新蜻蜓个体的位置;⑥更新领域半径,根据式(12)更新蜻蜓的步长向量;当有邻近蜻蜓时,根据式(13)更新位置向量,反之则根据式(14)更新位置向量;⑦判断是否满足终止条件,该条件为适应性达到稳定或迭代次数达到最大值;如果满足条件,则获得最佳超参数并结束,否则,下一次迭代更新.
Step7:根据通过DA 优化获得的最佳超参数,构造DA-Transformer风机叶片覆冰检测模型,并结合评估指标对检测结果进行分析.
本文所有风机叶片覆冰检测的数据驱动模型都是在基于Python 3.7.4架构下完成的.实验计算机系统为Win10 64位,CPU 为AMD Ryzen 7 4800 H Radeon Graphics 2.90 GHz,GPU 为NVIDIA Ge-Force RTX 2060,Tensorflow-gpu 版本为2.0.0,Keras版本为2.4.3.
2.1 数据来源和评价指标
实验数据由全球最大的风机制造商之一的金风科技公司提供.SCADA 系统记录了位于我国内蒙古的两台风机(分别记为WT#1和WT#2)的实时运行数据.有记录的WT#1和WT#2运行时间分别约为727 h和349 h,数据的分辨率为7 s.风机的原始传感器数据通常有数百个维度.然而,专业的风电工程师从这些收集的变量中选择了26个与风机叶片结冰相关的参数变量,见表1.此外,工程师还给出了结冰期和非结冰期的完整标签.

表1 来自SCADA系统的变量
本文选择的风机叶片覆冰检测的评价指标包括P(Precision)、R(Recall)和F1score.这些参数分别定义为
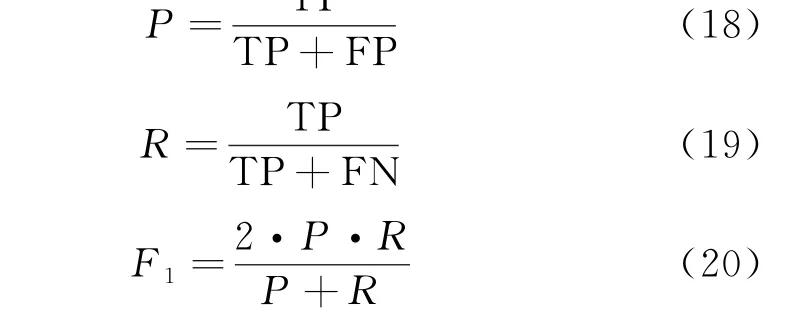
其中:TP、FP、FN 和TN 分别为真阳性、假阳性、假阴性和真阴性.由于识别尽可能多的结冰期至关重要,因此Recall性能比Precision更重要.F1用于评估整体性能,这是因为F1可以在Precision和Recall之间建立平衡.
2.2 变量选择和类不平衡处理
为了完成风机叶片覆冰检测任务,在进行输入变量选择时需要选择与结冰状态具有更大相关性的变量.对于DA-Transformer而言,变量选择的目的是从26个候选变量中选择S(S≤26)个变量.
本文使用基于决策树分类器的递归特征消除(RFE)[10]方法进行变量选择.RFE 通过递归删除特征并基于剩余特征来构建新的模型.它使用模型精度来确定哪些特征组合对预测目标特征贡献最大.但是,在应用RFE 时,很难确定要保留的最佳特征数量.针对这一缺陷,将4折交叉验证与RFE 相结合,对不同的特征子集进行评分,并选择最佳评分的特征集合.重复分层的4折交叉验证策略用于评估RFE的质量.应用此策略时,在每次重复之前对数据样本进行打乱,其中每个子集包含的每个目标类的样本百分比与完整数据集大致相同.对迭代过程中的评估结果进行平均,交叉验证的分数和特征数量之间的相关性如图4所示.

图4 带有4折交叉验证的RFE特征选择结果
从实验结果来看,最佳特征数为12个.此外,保留变量分别对应表1中编号为1、2、3、6、8、9、10、14、15、16、19和20的变量.绝大多数温度传感器变量被保留,而速度、风向、加速度和直流功率传感器变量被丢弃.这些结果与叶片结冰检测专业工程师的知识并不矛盾.值得指出的是,图4中的结果只能展示多个变量的累计交叉验证分数而无法表示每一个变量的重要性.
为了进一步验证提出的变量选择方法的有效性,以风机WT#1为例,进行各个变量与叶片覆冰状态之间的互信息相关性分析[5-6],分析结果如图5所示.
由图5可以看出所有变量分别与覆冰状态标签之间的相关性程度,根据互信息值由高到低进行排序并选择相关性程度最大的前12个变量,这些优选的变量依然跟本文提出的变量选择方法的实验结果一致.因此,即使在不考虑各个变量对覆冰检测的具体贡献程度的情况下,本文提出的基于决策树分类器的RFE变量选择方法也具有积极的工程应用价值.

图5 候选变量与覆冰状态之间的互信息相关性分析
以风速和风电功率为例,风机WT#1的实时运行数据如图6所示.

图6 风机WT#1运行状态的风速-功率散点图
由图6可知,正常样本和覆冰样本之间存在严重的类不平衡情况,即风机通常大部分时间都在正常条件下工作,叶片覆冰现象出现的情况较少.类不平衡的数据直接用于风机叶片的覆冰检测会干扰实验结果.
为了消除类不平衡的干扰,本文采用如图7所示的方法来生成平衡数据集,即对非结冰数据进行非重叠分割而对结冰数据进行重叠分割.分割窗口采用固定长度的滑动窗口,且该滑动窗口的长度为128(约为15 min).经过上述方法生成的正常样本和覆冰样本的个数均为2 736个,且每个样本是128×12的矩阵.值得指出的是,这里仅讨论了风机WT#1 的情况,风机WT#2的情况也类似,此处不再赘述.

图7 类不平衡处理方法
2.3 DA-Transformer模型的参数选择和优化结果
根据人工经验确定Transformer模型的部分超参数,包括:编码器层的层数为2、Dropout为0.5、学习率为0.005、优化器为Adam、激活函数为Relu.将经过类不平衡处理后的数据作为特征量输入到Transformer模型中,利用DA 算法来优化剩下的4个关键超参数,包括:epoch、batch_size和两个编码器层中神经元的数量(h1和h2).表2显示了优化过程中模型参数的配置.其中DA 的适应度函数是叶片覆冰检测结果的交叉熵损失函数,全部样本上的损失函数具体表达式为

表2 DA-Transformer模型的参数

式中:w是权重;m是样本个数;y i是样本i上真实标签;σi是样本i的sigmoid函数值.
传统的参数优化方法(例如:GA 和PSO 算法)存在过早收敛的缺陷,因此,本文使用DA 来搜索最佳超参数.训练集和验证集用于优化超参数的不同算法的对比实验.该比较实验在验证集中的适应度值结果如图8所示.
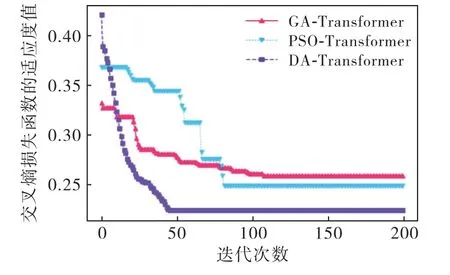
图8 不同参数优化算法的对比
上述算法的种群大小为20,迭代次数为200.在GA 中,种群的交叉概率为0.3,变异概率为0.8.在PSO 中,最大权重和最小权重分别为0.9和0.4,局部和全局学习因子分别为1.5和1.7.DA 将在47次迭代后收敛,并且获得的最小适应度为0.22.DA 的优化性能优于GA 和PSO,它可以通过更少的迭代获得更小的适应度值.优化后的Transformer模型剩下的超参数epoch、batch_size、h1和h2分别为37、63、38和26.
2.4 风机叶片覆冰检测结果
为了验证DA-Transformer对覆冰检测的性能,本文比较了6 个现有的基线模型,包括朴素贝叶斯(NB)[11]、一类支持向量机(OC-SVM)[12]、随机森林(RF)[13]、极端梯度提升(XGBoost)[14]、局部异常因子(LOF)[15]、卷积神经网络(CNN).需要注意的是,以上6种模型都可以应用于分类任务中.CNN 是一种基于深度卷积神经网络的图像分类器.多维的传感器数据可以视为图像,利用深度CNN 进行特征挖掘,在CNN 网络的后面同样采用全连接层和Softmax层,可以实现覆冰检测的结果.此外,对比的基线模型中还补充了DA-Transformer 的消融模型Transformer.
本文采用了结合人工经验和机器网格搜索的有效策略来定义优化上述所有模型性能所需的超参数.具有不同超参数组合的候选模型首先使用训练集进行训练,然后基于验证集进行评估.具有最低误差的模型被认为具有最佳超参数.选择的特定超参数是使用K折交叉验证的策略实现的.
最佳参数模型用于测试.重复试验10次,计算评价指标的平均值.当考虑风机WT#1和WT#2时,8个模型的测试结果见表3.

表3 不同模型覆冰检测结果的对比
由表3可知,深度学习模型比浅层模型的总体检测性能更好.然而,DA-Transformer模型的Recall和F1总是优于其它基线模型.这是因为DA-Transformer中的Transformer网络通过自注意力机制来挖掘数据的特征信息,它不仅能考虑局部信息还能考虑全局信息.此外,提出模型中的DA 智能优化算法能进一步提升原始Transformer 性能.与Transformer相比,DA-Transformer在风机WT#1 和WT#2中进行覆冰检测时,分别将F1提高了6.4%和4.7%.这说明了采用智能算法优化超参数不仅可以减少工程人员的工作量而且可以提升覆冰检测的效果.与CNN 相比,Transformer在风机WT#1和WT#2中检测时,分别将F1提高了1.2%和3.6%.这同样也说明Transformer比CNN 在时间相关性建模方面具有更明显的优势.因此,本文不再讨论智能算法优化CNN 的情况.
本文将NLP领域中机器翻译的Transformer模型引入到风机叶片覆冰检测领域.针对Transformer深度模型中难以确定最优超参数的问题,利用DA 智能算法来优化Transformer的部分超参数,从而进一步提升了Transformer模型的检测性能.实验结果表明提出的DA-Transformer模型在两个实际风机的覆冰检测任务中获得的分数(F1)分别高达93.0%和94.6%.本文的工作对提升风电工程技术人员的工作效率和检测效果具有一定的贡献.然而,本文研究的局限性在于DA-Transformer的检测结果依赖大量带有标签的数据样本.利用小样本机器学习来解决数据样本量有限的覆冰检测场景仍然有待进一步研究.
猜你喜欢 蜻蜓风机向量 向量的分解新高考·高一数学(2022年3期)2022-04-28风机用拖动大转动惯量电动机起动过程分析防爆电机(2021年3期)2021-07-21聚焦“向量与三角”创新题中学生数理化(高中版.高考数学)(2021年1期)2021-03-19汽轮机轴封风机疏水管线改造电子制作(2019年22期)2020-01-14船舶风机选型研究分析中国化工贸易·中旬刊(2018年6期)2018-10-21蜻蜓小天使·一年级语数英综合(2017年9期)2017-10-20蜻蜓点水小学生导刊(低年级)(2017年1期)2017-06-12向量垂直在解析几何中的应用高中生学习·高三版(2016年9期)2016-05-14蜻蜓阅读与作文(小学高年级版)(2016年5期)2016-05-10向量五种“变身” 玩转圆锥曲线新高考·高二数学(2015年11期)2015-12-23本文来源:http://www.zhangdahai.com/shiyongfanwen/qitafanwen/2023/0604/607215.html



