【www.zhangdahai.com--其他范文】
林锴,陶传奇,2,3,4+,黄志球,2,4
1.南京航空航天大学 计算机科学与技术学院,南京211106
2.南京航空航天大学 高安全系统的软件开发与验证技术工信部重点实验室,南京211106
3.南京大学 计算机软件新技术国家重点实验室,南京210023
4.软件新技术与产业化协同创新中心,南京210093
异常是指程序运行过程中出现的不可预期的错误。不适当的异常处理方法可能会无意中增加程序故障的风险,例如系统崩溃或者内存泄漏,因为异常在软件系统中很难被测试到。因此,有效的异常处理对于软件开发来说至关重要。Sawadpong 等人[1]的研究表明,异常处理产生的缺陷数量大约是总体缺陷数量的三倍。
目前大多数的编程语言,例如Java、C++、Python,都内置了异常处理机制来指导开发人员考虑程序中的异常路径,防止程序崩溃的发生。然而,如今的软件开发对API(application programming interface)库的依赖程度很高。一个API 库中包含了大量的异常类型以及异常处理的规则,例如Android 框架中就包含了超过260 个异常类型[2]。另外,热门的API 库的升级频率很高并且版本间改变较大。因此,每个方法所产生的异常类型及其处理方式,是软件开发过程中的重要活动。研究表明即使是经验丰富的开发者也经常会编写出错误的异常处理代码[3-4]。
异常处理代码推荐是指将try 语句块中捕捉的异常代码作为上下文信息,并针对上下文信息推荐合适的异常处理代码。推荐的异常处理代码可以是具体的语句块也可以是API 调用序列。现有的异常处理相关的推荐方法大多是利用启发式的规则或者统计学习的方法进行推荐。CAR-miner[5]通过挖掘try语句中的方法调用与catch 语句块中异常处理代码之间的关联规则为上下文代码推荐强相关的异常处理代码。FuzzyCatch[6]则是利用模糊逻辑理论分析每个API 调用可能产生的各种异常的概率,并根据异常发生概率的高低来检测代码可能存在的缺陷。除此之外,FuzzyCatch 还会为存在缺陷的代码推荐具体的异常处理API。以上方法大多从词法层面挖掘代码中的特征信息,忽略了语义信息。随着深度学习的发展,软件开发也逐渐走向智能化。一些研究将长短期记忆网络(long short-term memory,LSTM)应用于源代码中[7],LSTM 处理过长输入序列时,存在梯度爆炸以及梯度消失的问题[8]。自注意力网络[9]很好地解决了这一问题。目前,自注意力网络已广泛应用于自然语言处理领域。本文将自注意力网络应用于源代码中,提出了一种基于自注意力网络的异常处理代码推荐方法,即DeepEHCR。该方法不同于现有方法的地方在于它利用深度学习技术挖掘异常代码中各API 调用之间的深度特征信息进行异常处理的推荐。首先,DeepEHCR 利用API 调用树结构对上下文代码进行建模,并采用基于结构遍历算法将树转化为序列的同时充分保留树中的结构信息。其次,借鉴Li 等人[10]的方法,将异常处理的策略分为三类:处理异常、记录日志以及重新抛出。DeepEHCR 利用自注意力网络学习API 调用树中的特征信息,并根据这些信息推荐异常处理的策略。最后,针对处理异常这一策略太过抽象、缺乏针对性的问题,DeepEHCR利用Transformer 模型进一步推荐具体的异常处理API 序列。为了验证DeepEHCR 模型的有效性,分别对其异常处理策略推荐功能以及异常处理API 序列推荐功能进行大规模实验。本文从GitHub 中收集了1 524 个Android 项目,其中包含了55 763 个含有异常处理的代码块。这些代码按照9∶1 的比例划分为训练集与测试集。实验结果表明DeepEHCR 在异常处理策略推荐方面,Accuracy、Precision、Recall 以及F1-score 的值分别达到了89.78%、89.98%、89.34%以及89.59%。在API 序列推荐方面,Hit@1/3/5 的值分别达到了57.83%、69.73%、74.79%。最后,本文还将DeepEHCR 的整体性能和当前现有工作进行对比,DeepEHCR 在修复真实的异常漏洞方面明显地优于CARMiner[5]以及FuzzyCatch[6]。
本文的主要贡献包括:
(1)提出了一种新型的API 调用模型,该API 调用模型根据代码中的嵌套关系构建API 调用树以充分保留代码的结构信息。
(2)提出了一种基于自注意力网络的智能化异常处理代码推荐方法,该方法通过挖掘上下文代码中的深层次特征信息来推荐异常处理策略以及异常处理代码。
程序异常在软件工程领域被广泛地关注。许多研究人员对异常处理的代码与软件的鲁棒性的关系进行了研究[11-13]。Osman 等人[12]研究了异常代码的不同修改方式会对软件系统的鲁棒性产生怎样的影响。Marinescu[13]验证了使用到异常的类要比未使用异常的类更复杂,并且未正确处理异常的类要比正确处理异常的类出现漏洞的可能性高很多。
异常处理的复杂性导致开发者们在异常处理过程中产生了大量漏洞[10]。因此,近些年异常处理[5-6,14-16]引起了研究人员的较大关注。他们通过分析异常处理代码来帮助开发者们理解程序中的异常链以及编写异常处理的方式。
Li等人[10]将异常处理的策略共分为了四类:处理异常、记录日志、抛出和包裹并重新抛出。他们通过异常代码来推荐相关的异常处理策略。由于Li等人[10]是将整个方法块作为上下文代码,而本文默认捕获异常并且将try 语句块内代码作为上下文信息,Deep-EHCR 没有考虑抛出这一种情况。Zhong 等人[14]提出了一种方法Mono,用于修复异常相关的漏洞。它首先挖掘异常和修复方式之间的关联,然后建立每种异常的修复模型。CARMiner[5]利用代码搜索引擎从现有开源项目中收集相关的代码示例以增加数据量,并且结合一种新的挖掘算法,以序列关联的形式检测异常处理规则。DeepEHCR不同于CARMiner的地方在于它不仅考虑了上下文代码中的API 调用信息,而且捕捉了其中的结构信息。DeepEHCR 通过API 调用树挖掘异常代码中API 调用的潜在关联来推荐相关的异常处理代码。FuzzyCatch[6]利用模糊逻辑的算法预测代码中可能会发生的运行时异常,并且推荐相关的异常处理代码来修复异常。Fuzzy-Catch 通过分析每个API 调用产生异常的概率以及每种API 调用产生异常后对应的异常处理API 调用概率来预测异常以及推荐异常处理的API。它将上下文中的API 调用相互独立开进行分析,而DeepEHCR通过API 调用树结构充分考虑了上下文中各API 之间的潜在关联。考虑到异常处理中可能存在多个API 调用,DeepEHCR 推荐的异常处理代码为API 序列而不仅仅是单个API。
还有一些研究分析了异常对于程序全局的影响。Robillard 等人[17]针对当前Java 的异常处理机制,认为异常是全局问题并且很难提前定位异常源。Cacho等人[18]针对异常处理提出了一种面向切面的模型。该模型能够显式描述异常控制流的全局视图。DeepEHCR不同于这些方法的地方在于它是从局部出发,以try语句块作为上下文信息来推荐异常处理代码。
本章主要对异常处理代码推荐模型DeepEHCR进行介绍。图1 展示了DeepEHCR 的整体结构。该模型可以分为三个核心阶段:上下文代码表示、异常处理策略推荐以及异常处理的API 序列推荐。在上下文代码表示阶段,DeepEHCR 首先提取异常位置的上下文代码,即try 语句块内的代码。然后将上下文代码解析成抽象语法树(abstract syntax tree,AST),并进一步从AST 中提取API 调用树。之后利用基于结构的遍历算法(structure-based traversal,SBT)[19]遍历API 调用树。将遍历得到的序列与异常类型进行拼接,得到最终的上下文代码表示形式。在异常处理策略推荐阶段,异常处理共分为三种策略:处理异常、记录日志以及重新抛出。本文采用一种基于自注意力网络[9,20]的分类模型来将上下文代码映射到具体的异常处理策略中。在异常处理API 序列推荐阶段,DeepEHCR 会针对处理异常这一策略,利用Transformer 模型[17]推荐具体的API 序列,这些API 序列可以辅助开发人员编写正确的异常处理代码。记录日志策略和重新抛出策略不需要做进一步API 序列推荐,因为这两种策略的具体代码形式相对简单并且固定,不需要做出具体的代码推荐。除此之外,记录日志的方式有很多种,但是它们实现的功能是一样的,用户可以根据策略选择自己特定的记录日志方法来记录日志。

图1 DeepEHCR 整体框架图Fig.1 Overall architecture of DeepEHCR
2.1 上下文代码表示
2.1.1 API调用树
在做异常处理代码推荐前,需要对上下文代码进行特征表示。目前关于代码特征表示的研究大多是通过语法分析将代码转化成AST 的形式[7,21]。但是异常处理的代码通常会和try 语句块中特定的API 调用有关,因此本文采用API 调用关系来表示上下文代码。代码块是一种嵌套结构,它通过if、for 等控制流语句将代码中的语句分为不同的层次。图2 中的代码示例包含了三个层次:方法体中的代码块为第一层;
方法体中的for 循环语句为第二层;
for 循环中的while 语句为第三层。根据这种层次关系,本文提出了一种新型的API 调用树结构。API 调用树相比API调用序列的优势在于它充分考虑了代码中的结构特征,因此可以发掘出更多潜在的特征信息。

图2 代码示例Fig.2 Code example
API 调用树由控制流节点和API 调用节点组成。本文将控制流节点分为while、do-while、for、foreach、switch、if六类。它们在代码中的对应关系如图3。

图3 控制流与API调用节点对应关系Fig.3 Correspondences between control flow and API call nodes
While 节点表示一个while 语句,它包含两个子节点:Expression 节点和Block 节点。其中Expression节点表示while 语句中的条件表达式,它的子节点为条件表达式中的API 调用序列;
Block 节点表示循环代码块,它的子节点为循环代码块中的API 调用或者控制流语句对应的节点。Do-while 节点、For 节点以及Foreach 节点和While 节点类似,都包含Expression和Block 两个子节点。Switch 节点的子节点个数由其对应的语句块中case 语句的个数决定,每一个case语句对应一个Case子节点。If节点表示if-else语句块。它包含三个子节点,其中Expression 节点表示条件表达式;
Block 节点表示条件表达式为真时执行的语句块;
Else节点为表示条件表达式为假时执行的语句块。
根据以上API 调用树的定义规则,图2 中的代码块可以表示成图4 所示的层次结构。
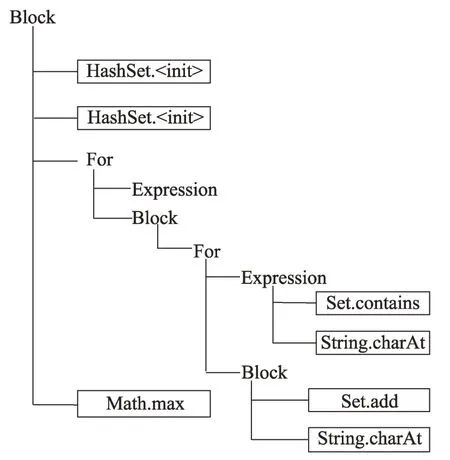
图4 API调用树结构Fig.4 Structure of API call tree
本文利用JDT 工具(http://www.eclipse.org/jdt/)来对代码进行解析。JDT 为Eclipse 内置工具,用于编译代码并生成对应的AST。根据代码的AST 模型,构建上下文代码对应的API调用树。
相对于AST 表示方法,API 调用树能够大量地减少树中节点的个数,还可以过滤掉大量无用的节点。这些无用的节点不仅会增加推荐模型的复杂度,而且会对模型的训练产生干扰。
2.1.2 API调用树遍历
为了将API 调用树输入到自注意力网络中,需要通过遍历API 调用树的方式将API 调用树转化为序列形式。可以选择先序遍历这样的经典树遍历算法来做序列化处理,但是这样得到的序列无法重构API调用树,因此损失了其中的部分结构信息。本文采用Hu 等人[19]提出的SBT 算法,以保证在遍历API 调用树的过程中保留树中的完整结构信息。图5 为SBT 的一个简单示例,它使用一对括号以及根节点来标识一棵树,然后递归地处理子树并将处理结果放入括号内。

图5 SBT 的简单示例Fig.5 Simple example of SBT
最后,本文将上下文代码对应的异常类型与API调用树对应的序列进行拼接,并通过分隔符进行区分。拼接后的词素序列被用来表示上下文代码。
2.2 异常处理策略推荐
2.2.1 异常处理策略分类
异常处理策略指的是根据特定的编程上下文代码应当采取的异常处理方式。Li 等人[10]将异常处理模式分为了四类:抛出异常(THROW)、处理异常(HANDLE)、记录日志或者忽略(LOG&IGNORE)以及捕捉并重新抛出(WRAP&RETHROW)。由于DeepEHCR 是在捕捉了异常代码块后执行的推荐,本文不考虑第一种情况,即抛出异常。除此之外,本文认为代码中捕捉了异常但不对异常做任何处理的方式是不合理的,因此对记录日志或者忽略这一类别进行了优化,去除了忽略不做处理的情况。为了提高数据质量,本文也将训练集中这样的样本剔除。最终本文将异常处理的策略分成表1 所示的三类。
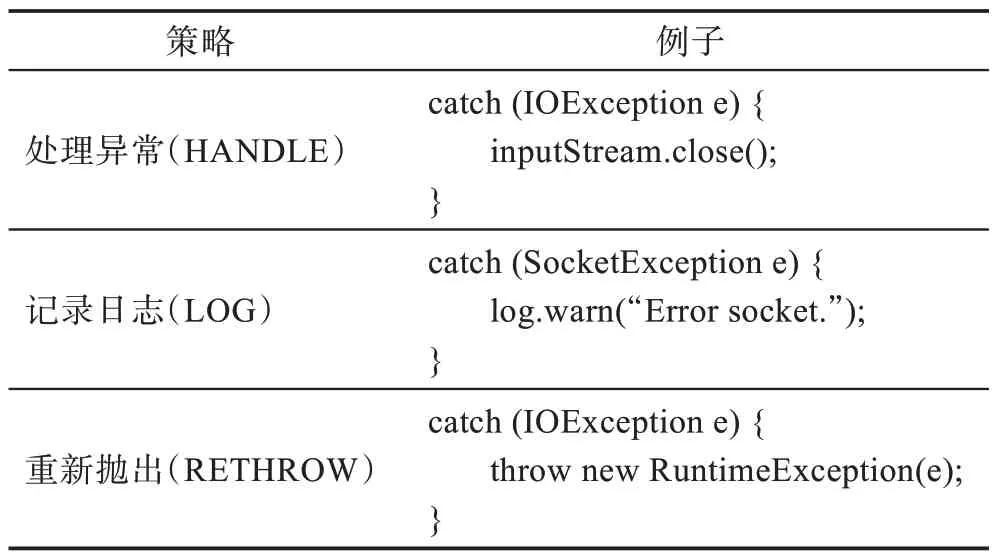
表1 异常处理策略Table 1 Exception handling strategies
2.2.2 异常处理策略推荐模型构建
本小节将详细介绍异常处理策略推荐模型,该模型利用自注意力网络从上一阶段词素序列中提取深层特征信息,对异常代码进行分类,最后将最优的异常处理策略推荐给开发者。自注意力网络[9]是为了解决传统循环神经网络(recurrent neural network,RNN)对于过长序列输入导致梯度爆炸以及梯度消失的问题。它可以很好地处理这种长依赖的情况[8]。除此之外,自注意力网络可以采用并行计算的方式来提升训练的速度。
首先需要对输入序列进行处理,将其转化为对应的词嵌入向量。词嵌入技术是将自然语言输入中的单词嵌入到低维向量空间的方法[22]。近几年,该方法也被应用到源代码处理的任务中,例如代码推荐[23-24]、注释生成[25-26]等。一般的做法是采用word2vec[27]词嵌入方法预先将每个词素转化为向量,但是本文的输入序列是从树中遍历得到,相邻的词素之间关系不大,因此将词嵌入向量作为参数形式与自注意力网络一同训练得到。由于自注意力网络中没有考虑词素与词素之间的位置关系,本文还加入了一个位置嵌入算法计算每个词素对应的位置向量。最后将词嵌入向量与位置向量相加得到词素序列对应的输入向量形式X=(x1,x2,…,xn)。
下面将对自注意力网络[9]进行详细介绍。每层自注意力网络都是由一个多头自注意力子层以及一个前馈网络子层构成。多头自注意力子层的结构如图6 所示。

图6 多头自注意力子层Fig.6 Multi-head self-attention sub-layer
多头自注意力子层使用多个自注意力函数来学习不同位置的不同子空间下的特征信息。由于每头只专注学习所在子空间的特征,效率和学习的效果都要比单头自注意力高很多。多头自注意力子层的计算公式如下:
其中,Q、K和V分别由输入矩阵X经过不同的线性变换XWQ、XWK和XWV得到,WQ、WK和WV为权重矩阵,dk为K的维度,KT为K的转置;
矩阵将Q、K、V映射到不同的子空间中;
Concat(h1,h2,…,hh)函数表示将参数中的多个矩阵按照第二维度进行拼接,例如hi∈,则Concat(h1,h2,…,hh)∈。
多头自注意力子层的输出会作为前馈网络子层的输入。前馈网络子层可以是全连接神经网络也可以是卷积神经网络。本文采用全连接网络作为前馈网络子层。它由两个线性变换以及一个ReLU 激活函数组成。
其中,W1、W2为权值矩阵,b1、b2为偏置项。
为了完成异常处理策略分类任务,本文将自注意力网络最后一层的输出转化为一维的向量,再经过线性网络以及Softmax 层输出分类结果。
其中,view函数用来重组矩阵,按照第一维的顺序将其转化为一维向量。W为权值矩阵,b为偏置项。
2.2.3 模型训练
本文需要对训练数据集进行处理。对于每个训练样本Code,根据Code中的异常代码(try 语句块内的代码)以及异常类型构建上下文信息的序列表示token_seq。异常处理代码对应的异常处理策略strategy则需要进行人工标记。为了保证标记的准确性,邀请了三名拥有多年Java 开发经验的学生来完成。除此之外,为了保证一定的客观性,本文还预先定义了一些标准。例如,如果异常处理代码中只包含log相关函数,则将其策略定义为记录日志。最终训练数据Code被表示成二元组形式
2.3 异常处理的API序列推荐
如果推荐的异常处理策略是记录日志或者重新抛出异常,用户可以轻松地根据策略来编写相对应的异常处理代码。但是,如果推荐的异常处理策略是处理异常,情况不会像前两种那样简单,因为用户只知道需要处理异常,并不知道具体的处理方法。为了更加全面地辅助用户编写具体处理异常的代码,本文还设计了一种API 序列推荐模型。在上一步得到了具体的策略后,针对处理异常这一策略进一步推荐具体的处理异常的API 序列,用户可以根据API序列来构建处理异常的代码。
2.3.1 异常处理的API序列推荐模型构建
异常处理的API 序列推荐模型使用的是Transformer模型[9]。该模型被广泛应用到自然语言处理等领域[28]。Transformer 模型主要由编码器和解码器两部分组成。编码器负责对输入序列进行编码,并将其映射到固定的维度空间中;
解码器负责将编码后的向量映射为目标序列。Transformer 模型的示意图如图7 所示。

图7 Transformer模型Fig.7 Transformer model
2.3.2 模型训练
本文首先需要对训练集进行预处理。对于每一个训练数据Code,分离出异常代码、异常类型以及异常处理代码,构成三元组形式
利用扫描的方式从catch_block中提取API 序列api_seq。最终Code被表示为二元组形式
Transformer 模型首先将词素序列token_seq作为输入,利用编码器对输入序列进行编码。解码器部分首先会生成特殊API
3.1 数据准备
本文选择从GitHub(https://www.github.com/)中下载原始代码数据。为了保证代码的质量,利用代码的获赞数作为选择的标准,因为代码的获赞数反映了代码的关注程度以及被其他编程人员认可的程度。一个代码的获赞数越高,它的质量往往也越高。本文只选择获赞数大于100 的Android 项目代码。如表2 所示,本文最终选取了1 524 个Android 项目,其中包含了55 763 个含有异常处理的代码块。另外,本文还对每种策略对应的代码块数以及所占的比例进行了统计。其中处理异常策略为19 542个,占总代码块数的35.0%;
记录日志策略为22 443个,占总代码块数的40.2%;
重新抛出策略为13 778个,占总代码块数的24.8%。

表2 实验数据介绍Table 2 Introduction of experiment data
为了训练和评估异常处理策略分类模型,对全部的55 763 个代码块按9∶1 的比例随机划分为训练集和测试集,其中训练集包含50 187 个数据,测试集包含5 576 个数据。由于异常处理API 序列生成模型针对的是处理异常这一策略,本文只选用处理异常策略的19 542 个代码块,同样采用9∶1 的比例进行划分。最后得到17 588 个训练数据以及1 954 个测试数据。
3.2 参数设置
本文的实验硬件环境为Intel i7-8700 3.2 GHz 处理器、GTX 1070 Ti的GPU以及32 GB内存的工作站。DeepEHCR 模型选用Python 语言以及Pytorch(https://pytorch.org/)深度学习框架实现。为了训练模型,将训练数据随机打乱并设置批次大小为64。本文选择词素出现的阈值为2,也就是说在训练集中出现次数大于等于2 的词素会放入到词汇表中。序列最大长度设置为100,对长度大于100 的序列进行截断,对长度小于100 的序列采用填充的方式补齐。对于网络模型的参数,自注意力网络的层数设置为3,自注意力共有4 个头,嵌入向量的维度设置为256,前馈网络的维度设置为了1 024。在模型中增加了Dropout机制使模型具有更好的泛化能力,Dropout被设置为0.1。表3 展示了详细的参数设置。

表3 参数介绍Table 3 Parameter introduction
3.3 评估指标
对于异常处理策略推荐,采用分类任务公认的四个指标,即准确率(Accuracy)、精确率(Precision)、召回率(Recall)以及F1 值(F1-score)来评估模型的有效性。
准确率是指在整个测试数据中,模型分类正确的数量占总数量的百分比。
其中,Ntotal表示测试数据的总数量,Ncorrect表示测试数据中被分类正确的数量。
精确率和召回率作为评估二分类问题的性能指标,也可以扩展到多分类问题中。在二分类问题中,精确率是指预测为正的样本中实际也为正的样本占被预测为正的样本的比例。
其中,TP表示正样本中预测为正的样本个数,FP表示负样本中预测为正的样本个数。
在n分类问题中,每次对一个分类计算,将这一类作为正样本,其余类作为负样本,执行一次二分类的精确率计算,最后对n次精确率计算的结果求加权平均值得到多分类情况下的精确率。
其中,Ntotal表示测试样本的总数量;
Label表示所有类别的集合;
Nl表示测试样本中类别为l的样本个数;
Precision2(l)表示类别l为正样本时的二分类精确率。
召回率在二分类问题中表示正样本中预测为正的样本占所有正样本的比例。
其中,TP表示正样本中预测为正的样本个数,FN表示正样本中预测为负的样本个数。
在n分类问题中,每次对一个分类计算,将这一类作为正样本,其余类作为负样本,执行一次二分类的召回率计算,最后对n次召回率计算的结果求加权平均值得到多分类情况下的召回率。
其中,Ntotal表示测试样本的总数量;
Label表示所有类别的集合;
Nl表示测试样本中类别为l的样本个数;
Recall2(l)表示类别l为正样本时的二分类召回率。
F1 值兼顾了分类模型的精确率和召回率,它可以看作模型精确率和召回率的一种调和平均值。
对于异常处理的API序列推荐,采用Hit@K(K=1,3,5)来评估模型的性能。
Hit@K(K=1,3,5)指的是推荐的K个结果中存在正确结果的样本占总测试样本的百分比。
其中,D表示测试数据集;
rankd表示正确结果在推荐列表中的排名;
I(·)函数为二值函数,当条件为真时值为1,否则值为0。
3.4 实验结果
3.4.1 基准实验
为了验证DeepEHCR 在异常处理策略推荐以及异常处理的API 序列推荐上的性能,本文构建了基于LSTM 的异常处理推荐算法。LSTM 是一种循环神经网络计算法,常用于自然语言处理当中。LSTM 通过引入输入门、遗忘门以及输出门来达到门控的目的,从而充分捕捉序列中的关联信息。除此之外,为了验证API 调用树提取的结构特征对于模型性能带来的优势,本文还构建了一个基于简单API 序列的自注意力网络模型来进行对比。该模型没有使用API调用树信息,而是顺序地从代码块中提取API 序列来表示。
最后,为了验证DeepEHCR 整体在异常代码处理上的优势,本文选择了FuzzyCatch[6]和CarMiner[5]两个当前最新的异常代码修复工具。FuzzyCatch[6]通过模糊逻辑算法预测代码中可能存在的运行时异常,并推荐相应的异常处理API。它不同于DeepEHCR的地方在于它只推荐一个API 作为异常处理代码。CarMiner[5]通过关联关系挖掘技术挖掘try 语句块中代码与catch 语句块中代码的关联规则,从而发现代码中可能存在的关于异常的漏洞。为了体现实验的客观性,本文选择了FuzzyCatch[6]中使用的关于异常漏洞修复的437 个存在异常的真实代码作为测试数据。对每一个存在异常代码,DeepEHCR 为其推荐相关的异常处理策略或者异常处理的API 序列,如果推荐的结果正确,这表示该异常修复成功。
3.4.2 异常处理策略推荐性能评估
表4 展示了上文提及的3 种不同异常处理策略推荐模型在准确率、精确率、召回率以及F1 值上的实验结果。LSTM 表示基于LSTM 的异常处理推荐算法,Self-Attention 表示未考虑结构信息的自注意力网络。DeepEHCR 在4 个指标上的值都接近90%,说明DeepEHCR 在异常处理策略推荐上的整体性能高,平均每进行10 次异常处理策略的推荐只会出现1 次错误。准确率方面,DeepEHCR 要比LSTM 和未考虑结构信息的自注意力网络分别高15.85 个百分点和4.52个百分点;
在F1 值方面,DeepEHCR 相较于LSTM 和未考虑结构信息的自注意力网络分别提升了17.6 个百分点以及4.54 个百分点。DeepEHCR 在异常处理策略推荐方面的性能要优于其他方法的原因在于,它不仅充分考虑了上下文信息中的结构,而且利用自注意力网络来挖掘API 调用之间的深层次的依赖关系。

表4 异常处理策略推荐实验结果Table 4 Exception handling strategy recommendation result 单位:%
表5 展示了3 种模型在时间性能上的对比结果。在推荐时间方面,3 个模型在5 576 个测试样本上完成推荐的总时间差不多,其中DeepEHCR 平均完成一次推荐的时间只需0.038 s。说明DeepEHCR在提升准确率的同时并没有增加耗时。

表5 3 种异常处理策略推荐方法的时间性能Table 5 Time performance of 3 exception handling strategy recommendation methods 单位:s
3.4.3 异常处理的API序列推荐性能评估
表6 展示了3 种异常处理的API 序列推荐方法在Hit@K(K=1,3,5)上的实验结果。从表中的实验结果可知,自注意力网络的性能要优于LSTM。在充分考虑上下文中的结构信息后,DeepEHCR在Hit@K上的得分相较于LSTM 以及未考虑结构信息的自注意力网络又有了明显的提升。具体而言,DeepEHCR在Hit@1 上的得分达到了57.83%,相较于LSTM 和自注意力网络,分别提升了10.77 个百分点以及3.56个百分点。DeepEHCR 的性能优于LSTM 的原因在于API 调用树SBT 后的序列要比正常序列长一倍以上,LSTM 很难捕捉这种长序列中的依赖关系,而自注意力网络通过多头自注意力的计算避免了长依赖消失的问题。综上所述,DeepEHCR在异常处理的API序列推荐任务上对比其余两种方法有明显的优势。

表6 3 种推荐方法在Hit@K 上的得分Table 6 Hit@K of 3 recommendation methods 单位:%
表7 展示了3 个模型在生成API 序列上的时间耗费。在推荐时间方面,3 个模型在1 954 个测试样本上完成推荐的总时间分别为271.1 s、301.5 s 以及314.2 s。平均每完成一次推荐花费的时间分别为0.139 s、0.154 s 以及0.160 s,虽然DeepEHCR 最慢,但是这种差距几乎可以忽略不计。

表7 3 种API序列推荐方法的时间性能Table 7 Time performance of 3 API sequence recommendation methods 单位:s
3.4.4 DeepEHCR 整体性能评估
本小节从DeepEHCR 整体出发,分析其面对真实异常代码的情况下推荐的性能。表8 展示了DeepEHCR 和其他两个对比方法在修复真实的异常漏洞方面的实验结果。在所有439 个存在异常漏洞的代码中,DeepEHCR 成功推荐了320 个异常处理代码用于修复异常漏洞,修复的准确率达到了72.8%,而CarMiner 和FuzzyCatch 分别成功修复了196 个(44.6%)异常漏洞以及287 个(65.4%)异常漏洞。实验表明DeepEHCR 在整体异常处理代码推荐的性能方面明显好于其余两个对比方法。

表8 异常漏洞修复结果Table 8 Results in fixing exception bugs
针对API 库的更新速度快、学习正确异常处理成本高的问题,本文提出了一种基于自注意力网络的智能化异常处理代码推荐方法DeepEHCR。该方法构建API 调用树来表示上下文信息,并利用自注意力网络推荐相应的异常处理策略。针对处理异常这一具体策略,利用Transformer 模型进一步推荐处理异常相关的API 序列。实验表明DeepEHCR 能够有效提取上下文信息并做出正确的异常处理代码推荐。
在未来的工作中,会优化推荐的异常处理代码形式,在异常处理的代码中增加结构信息。除此之外,为了更全面地分析模型的优势,会考虑构建不同编程语言的推荐模型。
猜你喜欢调用语句代码重点:语句衔接新世纪智能(语文备考)(2020年4期)2020-07-25核电项目物项调用管理的应用研究商品与质量(2019年34期)2019-11-29LabWindows/CVI下基于ActiveX技术的Excel调用测控技术(2018年5期)2018-12-09创世代码动漫星空(2018年11期)2018-10-26创世代码动漫星空(2018年2期)2018-10-26创世代码动漫星空(2018年9期)2018-10-26创世代码动漫星空(2018年5期)2018-10-26基于系统调用的恶意软件检测技术研究信息安全研究(2016年4期)2016-12-01如何搞定语句衔接题语文知识(2014年4期)2014-02-28利用RFC技术实现SAP系统接口通信中国信息化·学术版(2013年1期)2013-05-28本文来源:http://www.zhangdahai.com/shiyongfanwen/qitafanwen/2023/0923/658243.html



