【www.zhangdahai.com--其他范文】
汤 亮,张晓冰 ,成林芳
(1.湖南省电子信息产业研究院,湖南 长沙 410001;
2.杭州安恒信息技术股份有限公司,浙江 杭州 310000)
数据的不均衡分布即在数据集中有一个或者几个类别的样本数量远超其他类型的样本数。数据占比较小的类别称为少数类,占比较多的类别成为多数类[1]。网络攻击类型繁杂,有些攻击类型很常见如DDOS、暴力破解、ARP欺骗等。而有些攻击类型出现比较少,如未获授权的本地超级用户特权访问、远程主机的未授权的访问等。这些类型的攻击样本数比常见类型的攻击数量少[2-3]。不同攻击带来的后果也是不同的,DDOS攻击带来的后果可能是对整个网络破坏,降低服务性能,阻止终端服务,而远程主机的未授权访问会导致主机被控制从而进行违法犯罪活动等。现有的分类方法对于多数类别的样本点识别率高,而少数类别易被误分类,从而导致很严重的后果。因此处理不平衡数据集,提高模型泛化性能是很重要的。
学术界提出了许多针对不平衡数据集的处理方法,主要分为两类,第一类是在数据层面,第二类是在算法层面[4-5]。对于数据层面,增加少数类别样本降低不均衡性称为过采样[6-8],减少多数类别样本称为欠采样[9-10]。欠采样中典型的方法是随机删除多数类别的样本,但是由于样本的大部分特征相似,随机删除可能会删除重要的信息,导致模型泛化性能差。过采样中典型的方法是连续复制少类别样本数,达到类间平衡,但是因为有大量重复的样本点,可能会导致过拟合。为了防止上述问题,Chawla等人提出了的人工合成新样本点的SMOTE算法[11],在每个样本的特征空间中挑选K个近邻,使用随机因子选出一个每个近邻与样本之间的点成为新的样本点。有效地增加了少数类别样本点的数量,但是对于多数类别的样本不产生影响,若一个少数类别样本点附近都是多数类别容易产生噪声,影响对于数据集的分类效果。而Hui等人提出的基于边界线的过采样算法[12](Borderline-SMOTE),对距离边界较近的样本点根据SMOTE的原理,对模糊样本点进行过采样,可以确定边界样本的类别。但是这种方法只针对了边界样本,忽略了类内样本分布的问题,类内分布不均衡时也会导致样本点重合,难以提供有效的分类信息。
在算法层面,学者提出了很多基于传统分类器的算法,但是所有传统分类器的目的都是减少整体的损失或漏报率。他们大都认为所有类别误分类的代价相同。但是网络攻击中误分类的代价可能导致系统崩溃,重要信息被篡改等,这些代价是远超我们想象的。Khan等提出的基于代价敏感的特征算法,对于CNN模型中特征和分类器的训练过程进行改进,增加学习特征的判别性,和鲁棒性。但是代价敏感学习中代价参数的设定需要有先验经验,因此很难准确设定,从而使分类结果。基于单类学习的不均衡数据处理算法主要针对多类别样本进行学习,它的目标是从测试的样本中选出多数类,因此虽然可以降低时间成本,但是在对类间不均衡对少数样本过拟合,从而使模型泛化性能差。
从数据预处理方面与增强学习融合构成分类器,提出了基于CanpoySMOTE和AdaboostM1的入侵检测分类方法,首先使用Canpoy进行粗聚类得到噪声点,去除噪声点,同时使用降采样方法将多数类别的数量降低,减少模型过拟合,然后用SMOTE线性合成少数类样本点,提高了少数类别的数量,从而减少了类间不平衡,形成平衡数据集,该平衡样本可以很好地弥补少数类别分类样本数量不足的缺点,又解决了随机采样时重要信息丢失的问题。与AdaBoostM1分类器结合,使用随机森林作为基分类器,随机选取特征子集的特性让数据维度对分类结果的影响降低,在每次迭代的过程中获得局部最佳弱分类器,然后对样本的权重进行更新,虽然训练时间会增大,但是与原来的不平衡数据集在AdaboostM1分类器上的结果相比,可以有效地提升少数类别的准确率,降低平均漏报率。
首先使用Canopy算法[13]将训练数据根据欧氏距离计算样本点到簇中心点的距离,分为多个Canopy子集,将包含样本点较少,距离较远的子集视为噪声点,删除这些噪声数据,然后对多数类进行随机降采样,降低模型过拟合,最后通过SMOTE抽样对训练集进行类内均衡,得到均衡数据集,算法流程图如图1所示。

图1 平衡数据集构造流程图
1.1 Canopy
Canopy是一种简单的粗聚类算法,使用欧式距离计算样本点到质心的距离,与设定的距离阈值T1,T2进行比较。最后根据每个簇中样本点数以及与每个质心的距离筛选出数据集中的干扰点,并删除噪声样本。算法步骤如下:
(1)将原始样本集随机排列成样本列表L={x1,x2,…,xn}根据先验知识或交叉验证调参设定初始距离阈值T1,T2(T1>T2)。
(2)随机从列表L中选取一个样本点xi,i∈(1,n),作为第一个Canopy的质心,并把x1从列表中删除。
(3)随机从列表L中选取一个样本点xp,p∈(1,n)p≠i,计算xp到所有质心的距离,并检验最小距离Dmin。
(4)若T2≤Dmin≤T1,则给xp一个弱标记,表示Dmin属于此canopy,并加入。
(5)若Dmin≤T2,则给xp一个强标记,表示Dmin属于此canopy,且接近质心;
并将xp从列表中删除。
(6)若Dmin>T1,则xp形成一个新的局促,并将xp从列表中删除。
(7)重复第三步,直到列表中元素数变为零。
删除canopy簇中样本点数少的簇,并将少数类样本点附近有超过一倍多数类样本点的噪声点删除。
1.2 人工少数类样本点合成算法
SMOTE算法,该算法只对少数类别的样本起作用[14-15]。主要思想是通过随机寻找少数类样本点,在距离该样本点k个最临近类中寻找一点,进行插值,合成新的少数类实例,样本数少的类别进行人工合成新的样本加入训练集中。该算法合成数据的步骤如下:
(1)从数据集中挑选出一个少数类别的样本i,特征向量为xi,i∈{1,…,T};
(2)从少数类别的全部T个样本中找到样本xi的k个近邻(例如使用欧氏距离),记为xi(near),near∈{1,…,k};
(3)从这k个近邻中随机选取一个样本xi(nn),再生成一个(0,1)之间的随机数λ1,从而合成一个新样本xi1:
xi1=xi+λ1·(xi(nn)-xi)
(1)
(4)将步骤3重复N次,从而可以合成N个新样本:xinew,new∈{1,…,N}。
对于网络数据集来说,不同类型的攻击所引起的代价不同,传统的单层决策树保持不变的训练数据每次迭代找到的都是最好的点,也都是同一个点。因此模型的分类精度低,泛化性能差。而AdaBoostM1可多次迭代训练弱分类器,把错分类样本数量权值进行调整,提高分类模型的泛化性能。每一次训练好的弱分类器将会参与下一次迭代训练。根据上一次迭代结果增大误分类为多数类的样本点在训练集中所占权值,同时把正确分类样本点的权值减少,并进入下一次迭代,可以有效地提高分类器的分类性能。下一次迭代产生的分类器更加关注上一个分类器分类错误的样本,增加了样本分类的正确率,最后根据每次迭代产生的分类器进行投票决定分类结果。每次迭代产生的分类器根据分类错误率来计算最后组成强分类器时所占比重。分类错误率越低,权重越高。因此使用AdaBoostM1可以有效降低分类错误率,提高少数类别的分类准确率,使模型的泛化性能更好。
本文使用随机森林作为弱分类器,对于一个输入样本会产生多个分类结果,最终分类结果由随机森林中每个树投票产生。随机森林因为它是随机选取特征子集,因此减少了维度过多带来的影响,使模型训练的效果更好,增加鲁棒性。AdaBoostM1框架如图2所示。
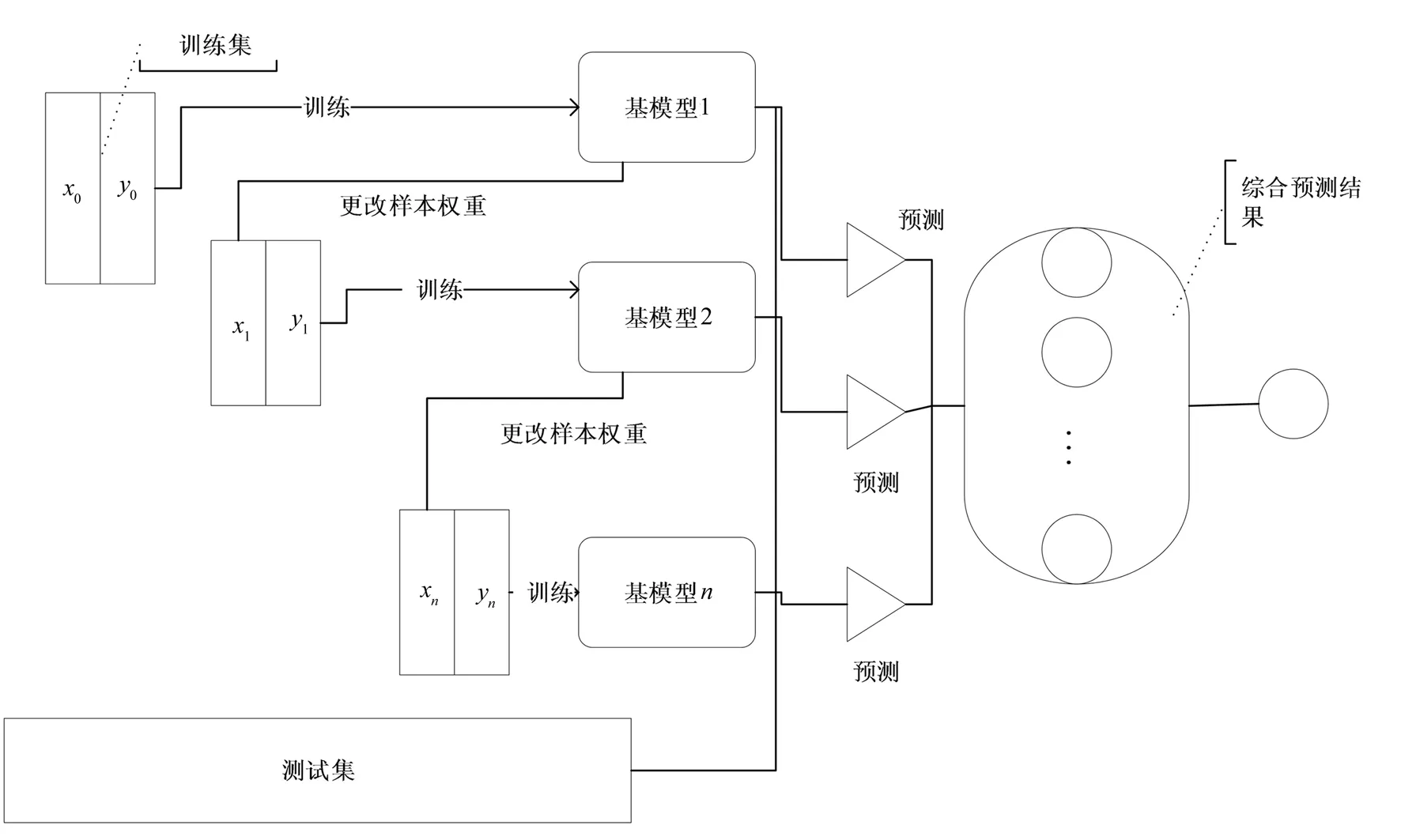
图2 AdaBoostM1框架流程图
3.1 数据集
实验使用数据集为KDD CUP 99数据集。该数据集含有大量网络流量数据,大概包含有5,000,000多个网络连接记录,同时包含有测试数据大约2,000,0000条。为避免数据量过大,按10%比例对数据集进行随机抽样,把抽样结果作为学习的训练集,使用测试数据的10%作为测试集。可以有效地减少建立模型的时间,同时在精度上影响较小[16]。本文使用的训练数据集包含49,399条训练数据。测试集包含311,029条测试数据记录。数据集中共有41个特征,4种攻击类型,分别是拒绝服务攻击(Denial of Service,DOS),源于远程主机的权限获取攻击(Remote to Local,R2L),端口监视扫描攻击(PROBE),提权攻击(User to Root,U2R)。具体数据集攻击类型数目分布如表1所示:

表1 原始数据集类型分布
由于原始数据集中样本不平衡,U2R的数量远远少于DOS和Normal,因此会对结果造成影响,影响模型的泛化性能,采用Canopy去除噪声点,SMOTE来提高少数样本U2R和R2L的样本数量,同时对含有较多记录的DOS和Normal类型进行降采样,然后将人工合成的U2R和R2L类型的记录与降采样得到的数据和Probe类型的数据混合成一个新的平衡数据集。本文使用的均衡数据集数据分布如表2所示:
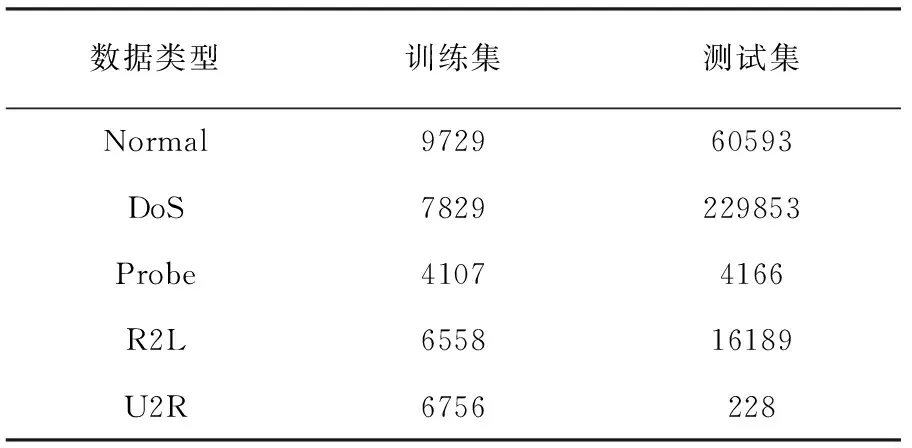
表2 平衡数据集分布
3.2 实验结果的评估准则
本文使用混淆矩阵、漏报率、ROC曲线来对分类器进行评价[17]。混淆矩阵也叫作误差矩阵,用来比较分类结果跟实际结果,是可视化描绘出分类器性能的指标。
漏报率、准确率计算公式如下:
漏报率=把某类攻击样本判断为正常样本的数量(FP)/该类攻击样本总数
(1)
准确率=所有预测类别正确的样本数量(TP+TN)/所有类别总的样本数量
(2)
ROC曲线横轴是伪阳性率FPR,纵轴真阳性率TPR。
(3)
真阳性率或真正性率表示模型把正常样本预测为正常样本的数量与所有预测为正常样本数量的比值。
(4)
伪阳性率或假正性率FPR表示模型把正常样本预测为攻击类型的数量与所有预测为攻击类型的样本的数量的比值。
ROC曲线通常用来表示模型分类器的效果,在最佳状态下,ROC应该在左上角,这表示在较低假阳率的情况下有高真阳性率。
将随机抽样得到的不平衡训练集使用10折交叉验证,把数据集中的数据均等分为10份,选取一份做验证集,其余9份做训练,依次迭代10次。最后使用10个模型的平均实验结果作为整个模型的结果,使用测试集进行测试,将在此训练集中训练的模型命名为AdaboostM1。将平衡数据集使用10折交叉验证,把随机森林作为基分类器,随机森林能够处理高维度数据不需要进行特征选择,对于不平衡的数据集可以平衡误差,因此可以与AdaboostM1进行结合。
把在平衡数据集上训练得出的模型命名为SMOTEAdboostM1,在原始数据集上训练得出的模型命名为AdaboostM1。使用测试集分别对两种模型进行检验,SMOTEAdboostM1模型得到混淆矩阵如表3所示,AdaboostM1模型得到的混淆矩阵如表4所示。表5是AdaboostM1模型和SMOTEAdboostM1模型在测试集上进行测试得到的每个类别漏报率结果。表6是AdaboostM1模型和SMOTEAdboostM1模型在测试集上进行测试得到的每个类别准确率结果。
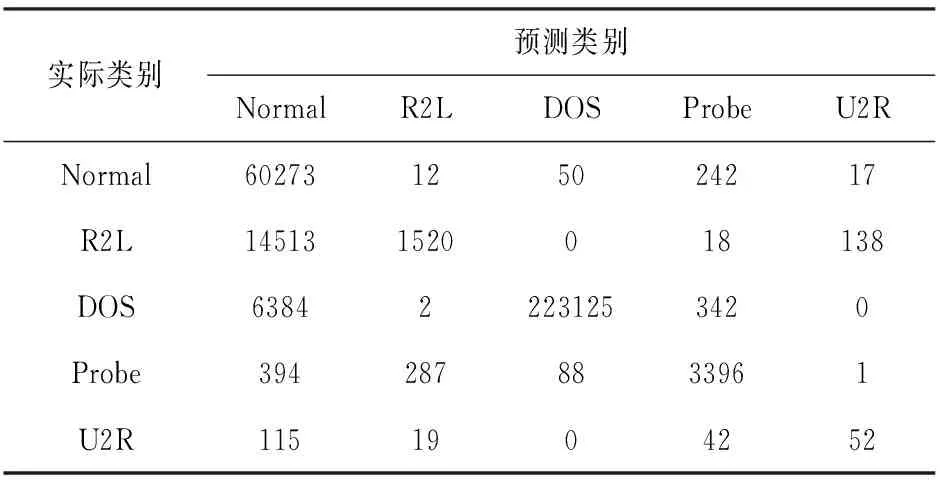
表3 SMOTEAdboostM1混淆矩阵
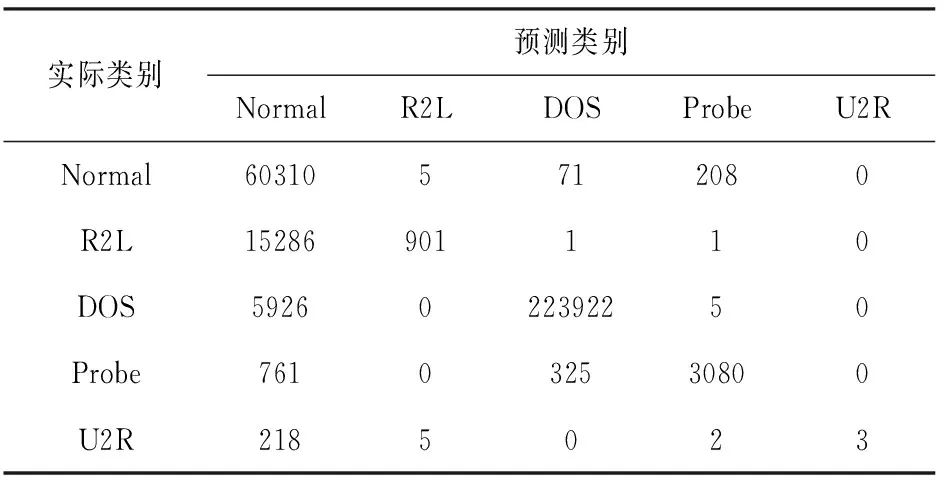
表4 AdaBoostM1混淆矩阵
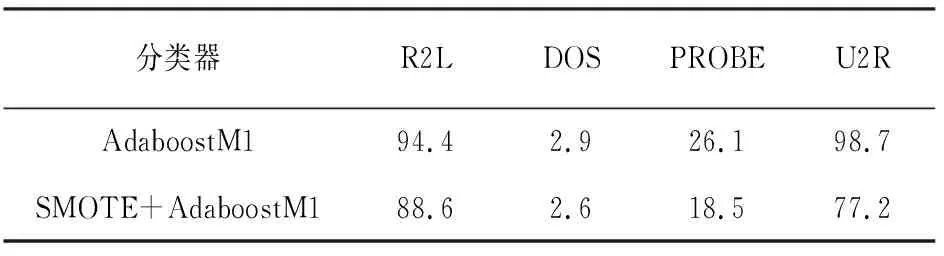
表5 AdaBoostM1与SMOTEAdboostM1漏报率(%)
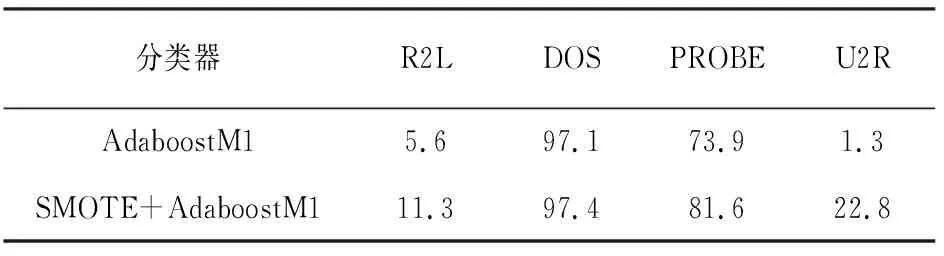
表6 AdaBoostM1与SMOTEAdaBoostM1准确率(%)
通过表5和表6数据表明在使CanpoySMOTE对样本处理之后,减少了噪声,解决了样本不平衡造成的少类别样本误差问题。在没有改变原有整体准确率的前提下,极大地提高了U2R、R2L的准确率,同时减少了漏报率。
为了进一步表明,本文提出的方法对少类别数据有较好的应用,本文还比较了U2R和R2L在两个模型上的ROC曲线。数据集中的少数类别U2R在SMOTEAdaBoostM1模型上的ROC曲线如图3所示,AUC=0.9779。

图3 SMOTEAdaBoostM1-U2R ROC曲线
数据集中少数类别U2R在AdaBoostM1模型上的ROC曲线如图4所示,AUC=0.6297。
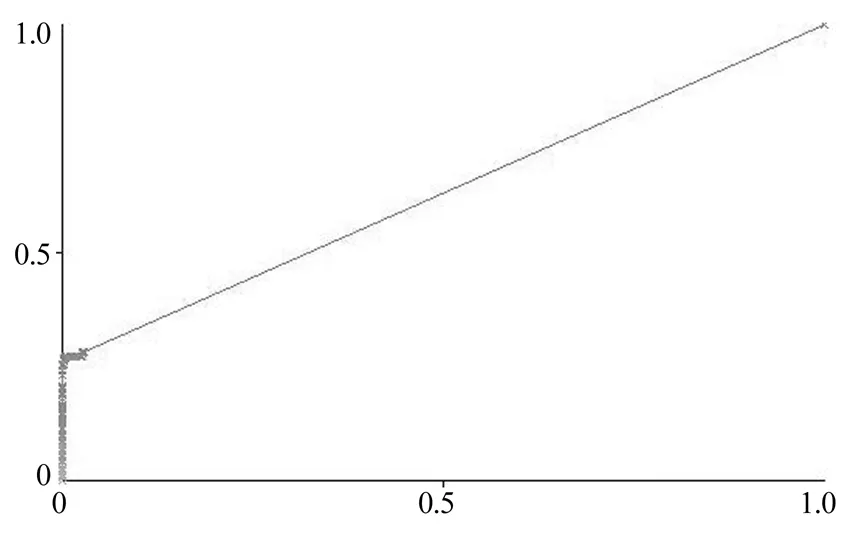
图4 AdaBoostM1-U2R ROC曲线
数据集中少数类别R2LSMOTEAdaBoostM1模型上的ROC曲线如图5所示,AUC=0.7091。

图5 SMOTEAdaBoostM1-R2L ROC曲线
数据集中少数类别R2L在AdaBoostM1模型上的ROC曲线如图6所示,AUC=0.6486。
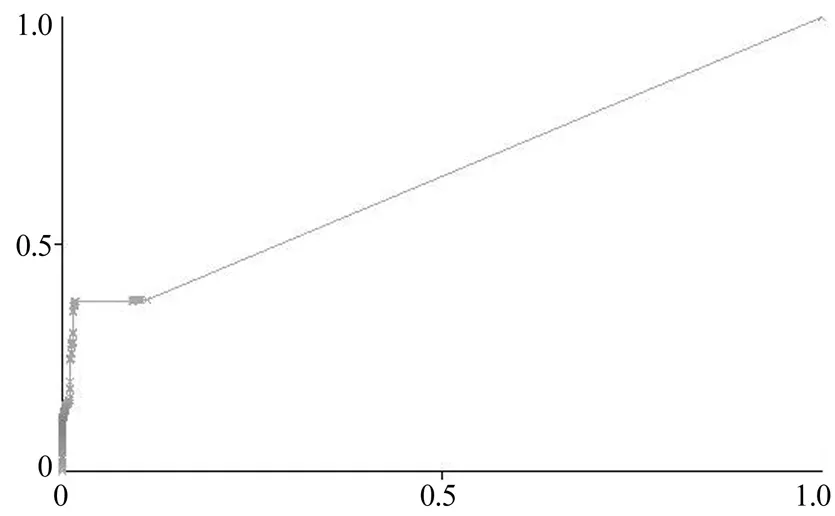
图6 AdaBoostM1-R2L ROC曲线
网络环境中攻击行为多种多样,收集到的攻击数据样本数量不均衡,很难对少数类别的攻击行为进行判断,因此本文中使用Canopy去除噪声点,减少了在合成少数类别样本点时的误差,SMOTE技术将某种攻击数据量少的类别(R2L和U2R)进行人工合成数据,增加数据所占比例,并同时减少数量占比较多的类别(DOS和Normal)样本的数量,然后使用平衡数据集训练AdaboostM1分类器,与原始数据集在AdaBoostM1分类器上训练模型进行对比。实验得出在不减少整体数据集准确率的情况下,少数类别U2R攻击的准确率提升20%,R2L攻击的准确率提升5%,同时平均漏报率降低9%,证明了该方法可以有效提升少类别准确率,降低平均漏报率,有效地解决了网络入侵检测少数类误分类问题。
猜你喜欢漏报类别分类器加权空-谱与最近邻分类器相结合的高光谱图像分类光学精密工程(2016年4期)2016-11-07结合模糊(C+P)均值聚类和SP-V-支持向量机的TSK分类器光学精密工程(2016年3期)2016-11-07各类气体报警器防误报漏报管理系统的应用中国质量监管(2016年10期)2016-07-10服务类别新校长(2016年8期)2016-01-10论类别股东会商事法论集(2014年1期)2014-06-27传染病漏报原因分析及对策卫生职业教育(2014年20期)2014-05-16基于LLE降维和BP_Adaboost分类器的GIS局部放电模式识别电测与仪表(2014年15期)2014-04-04中医类别全科医师培养模式的探讨中国中医药现代远程教育(2014年16期)2014-03-01日本厂商在美漏报事故千余起被指管理疏漏湖南安全与防灾(2014年12期)2014-02-27历次人口普查中低年龄组人口漏报研究中共党史研究(2013年9期)2013-04-27本文来源:http://www.zhangdahai.com/shiyongfanwen/qitafanwen/2023/0923/658244.html



